[Day 133] Gathering data for the Scottish dataset project + Factor analysis + Grokking ML + MLxFundamentals Day 4 (2)
Hello :)
Today is Day 133!
A quick summary of today:- started putting together some audio clips + transcription for the Scottish dataset project
- saw how eigenvalues play a role in factor analysis
- started reading Grokking Machine Learning on Manning.com
- finished MLx Fundamentals' final session
Firstly, about the audio data
My Scottish partner for this project has recorded various phrases in Glaswegian in the past and uploaded them to youtube. Today I did 4 of the 10 videos.
To cut the clips I ended up using an app called VideoPad, and even though it is a paid app, it allows me to just cut an audio clips in smaller pieces and save them as new files.
This is a sample audio waveform of one of the 4 videos

Secondly, today I read about eigenvalues' role in factor analysis
In my stats class at uni, we learned about factor analysis, and at the end of the chapter I saw the word eigenvalues, and I am glad because once again I will see their real world impact (after my dive into multicollinearity).
Firstly, about factor analysis, here are the results after using unstandardized variables
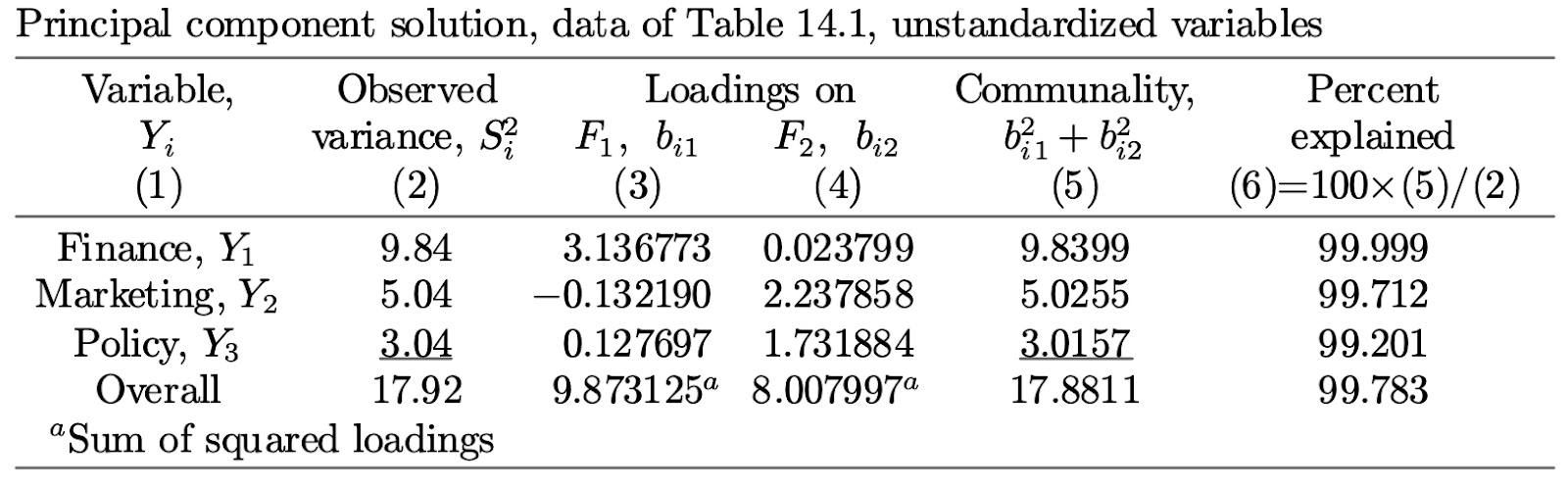

- result interpretability
- helps with linearity
- treats variables equally

The eigenvalues can help to determine which factors to keep (i.e. using scree plots).
Love it when I see the math I studied for ML being used in practice, and *where* it is used.
Thirdly, about Grokking ML
I decided to subscribe to manning.com and the 1st book I decided to read was Grokking ML (as it is one of the most recommended and popular ones). Today I managed to read the 1st 4 chapters(what is ML, types of ML, linear regression, optimization), and I can definitely see why it is popular for beginners, and I am excited to keep reading.
Finally, the last session from MLxFundamentals was delivered by Wenhan Han a PhD candidate from TU Eindhoven.
It was about loading and using an LLM, and a diffusion model
Some interesting bits from both parts are:
Question to an LLM:
How many kinds of human beings are there in the history?
We saw the top answers from the model.

Zero-shot




We add LoRA adapters



Train the model


For finetuning I need to try unsloth by myself. For some part of the tutorial, an openai api key was required which was unfortunate because I do not have one, so I just watched that part.
As for diffusion models

I saw the library 'diffusers' was used which I did not know.


That is all for today!
See you tomorrow :)

