[미리 공부] 기초 통계 복습 (Day 1는 1월2일)
모험을 시작하기 전에 기초 지식을 복습하고자 했다.
오늘 SPSS 대안 프로그램을 찾아보려고 해서 JASP에 대해 알게 되었다. 유용한 프로그램인 것 같아서 선회귀와 기술통계를 내려고 했는데 재미있었다. 그런데 JASP에 대해 더 알기 전에 '기초 통계 지식을 좀 복습을 하고자 하면 좋을 것 같아'란 생각을 들었다.
다행히, Coursera에서 Stanford University의 Guenther Walther 교수님께서 진행된 Introduction to Statistics 무료 강좌가 있다.
좀 부족한 부분은 다양한 검정통계 하는 거고 (F test, t-test, chi-square 등) 이제 JASP 아니면 다른 통계 프로그램 사용하게 되어도 이런 부분을 좀 더 자세히 집중하여 공부하면 된다.
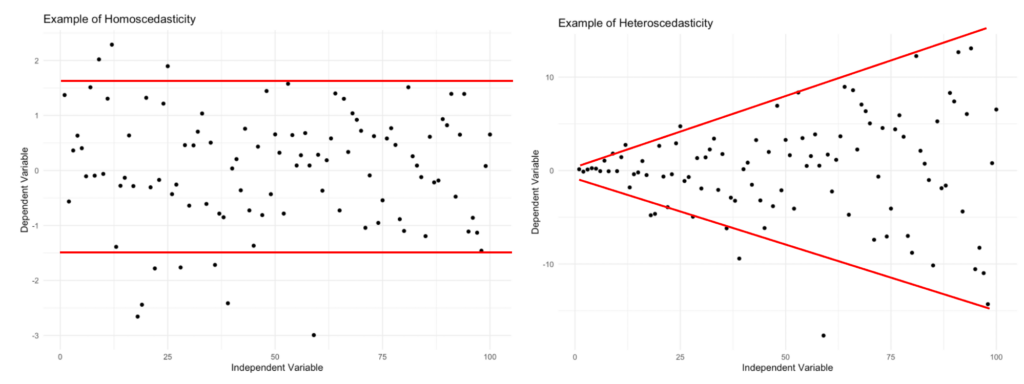
특히 homoscedasticity 및 heteroscedasticity 개념을 기억에 남았다.
Homoscedasticity (선):
- Definition: In a homoscedastic dataset, the variance of the errors (residuals) is constant across all levels of the independent variable(s). In simpler terms, the spread of the residuals is the same throughout the range of predictor values.
Heteroscedasticity (악):
- Definition: Heteroscedasticity occurs when the variance of the errors is not constant across all levels of the independent variable(s). In other words, the spread of residuals changes as the values of the independent variable(s) change.
(Udemy 사진)
강의 커리큘럼이 다음과 같다:
- Introduction and Descriptive Statistics for Exploring Data
- Producing Data and Sampling
- 샘플링 개념 및 실험 설계에 대한 탐색
- 간단한 무작위 샘플링, 편향, 관찰 대 실험, 그리고 무작위 대조 실험과 같은 주제 내용
- 특별 산업 인사이트로 특허 출원에 대한 내용
- Probability
- 확률의 정의 및 간단하고 복잡한 도전 과제를 해결하기 위한 필수 확률 규칙 학습
- 보완, 동일한 가능한 결과, 덧셈 및 곱셈과 같은 주제 내용
- Normal Approximation and Binomial Distribution
- 데이터에 대한 경험적 규칙과 정규 근사에 대한 모듈
- 정규 곡선, 데이터 표준화, 이항 분포 및 무작위 변수의 기초 내용
- Sampling Distributions and the Central Limit Theorem
- 대수의 법칙과 중심 극한 정리에 대한 학습
- 모수와 통계량의 차이, 기대값 및 표준 오차와 같은 주제 내용
- Regression
- 회귀에 대한 소개, 상관 계수, 회귀선 및 회귀 진단에 대한 모듈
- 예측, 회귀에서의 평균 회귀, 이상값 및 영향력 있는 점과 같은 주제 내용
- Confidence Intervals
- 표준 상황에서 신뢰 구간 생성 및 해석에 대한 모듈
- 중심 극한 정리를 사용하여 신뢰 구간 찾기 및 부트스트랩 원리를 사용한 표준 오차 추정과 같은 주제를 내용
- Tests of Significance
- 가설 검정 논리 및 다양한 샘플과 상황에 대한 적절한 통계 검정 수행에 대한 모듈
- 가설에 대한 p-값, t-검정, 통계적 중요성 대 중요성과 같은 주제내용
- Resampling
- 컴퓨터 집약적인 통계 추론에서 사용되는 몬테카를로 방법과 부트스트랩 방법에 중점을 둔 모듈
- 이러한 방법 뒤의 이론적 원리 및 회귀 및 신뢰 구간 생성과 같은 다양한 맥락에서의 적용에 대한 학습
- Analysis of Categorical Data
- 범주형 데이터에 대한 세 가지 중요한 통계 분석에 중점을 둔 모듈
- 두 가지 범주형 변수 간의 관계, M&M의 색상 비율 및 동질성, 독립성을 검정하는 카이제곱 검정 내용
- One-Way Analysis of Variance (ANOVA)
- ANOVA의 기초 및 일원 ANOVA 예제에서 F-검정에 대한 모듈
- 여러 평균 비교, ANOVA 평가를 위한 F 분포 사용 등 내용
- Multiple Comparisons
- 빅데이터 시대에 나타난 데이터 스누핑과 다중 검정 헛갈에 중점을 둔 모듈
- 데이터 재현성과 적용

