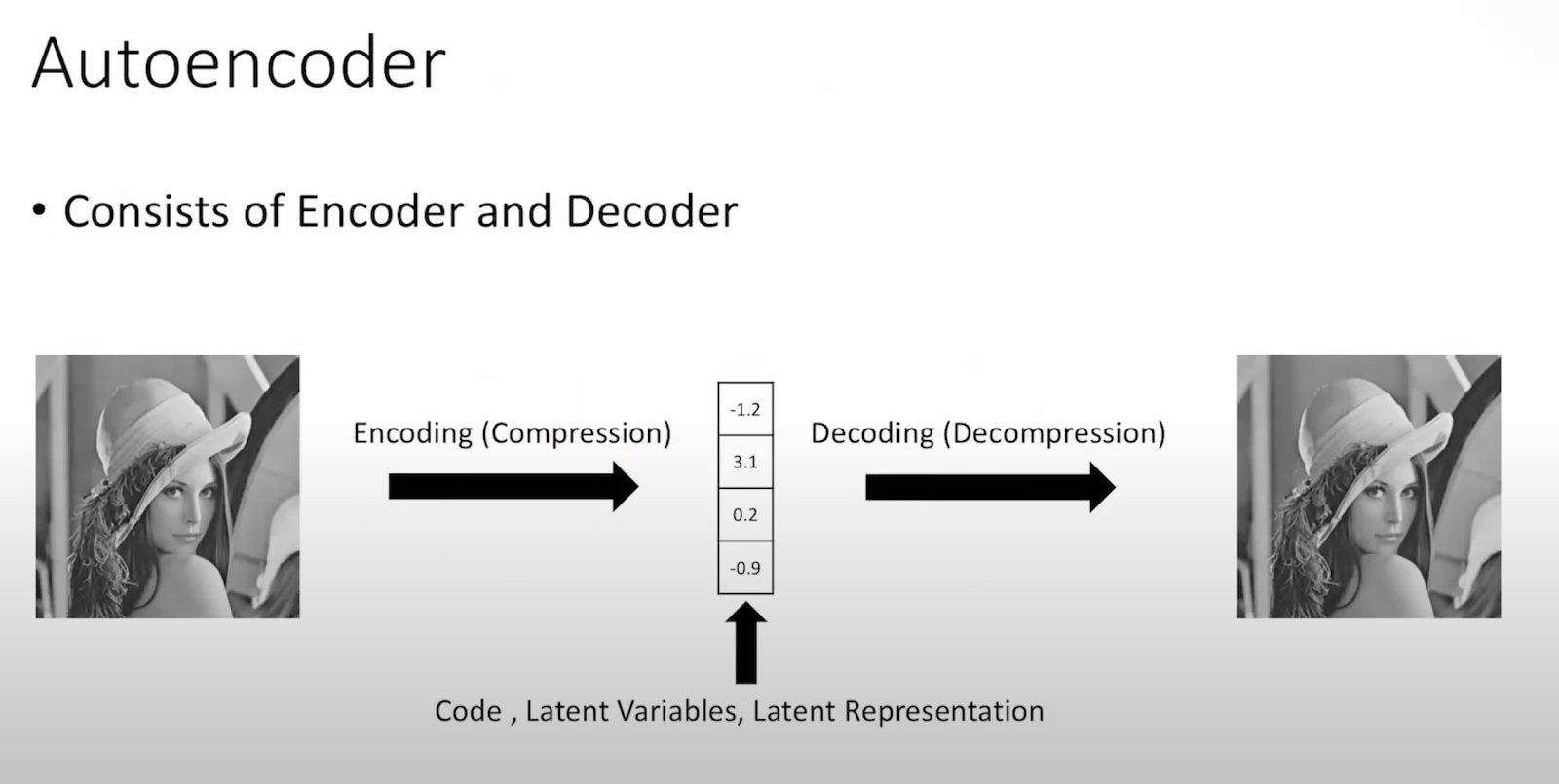
[Day 46] Meeting Transformers again and their implementation

Hello :) Today is Day 46! Understanding Transformers with Professor Choi from KAIST The first time I learned about transformer was Day 32, it was a simple intro, but I did not understand exactly what is happening. I felt like, I was just made aware of their existance in the NLP world. This img is from Andrew Ng's Deep learning course. In a transformer, the data goes through encoder-decoder network. In the encoder: for each token its attention is calculated according to the other tokens. And This attention mechanism allows the model to weigh the importance of each token in the context of the entire sequence. This information is put through a feed forward network that extracts deeper features. In the decoder, we start to predict words. For example we start with an <start of sentence> token, then we pass that at the bottom, then from the encoder we take the K(key) and V(value) and with the Q(query) from the decoder input, we try to predict the next item in the ...