[Day 45] Trying to understand VAEs with Professor Choi from KAIST
Hello :)
Today is Day 45!
A quick summary of today:- Learning the theory behind VAEs with Professor Choi from KAIST
- Implementing a VAE from scratch with Aladdin Persson (now probably my 2nd favourite DL youtuber after Andrej Karpathy)
1) Theory behind Variational Auto Encoders (VAEs)
we begin with autoencoders
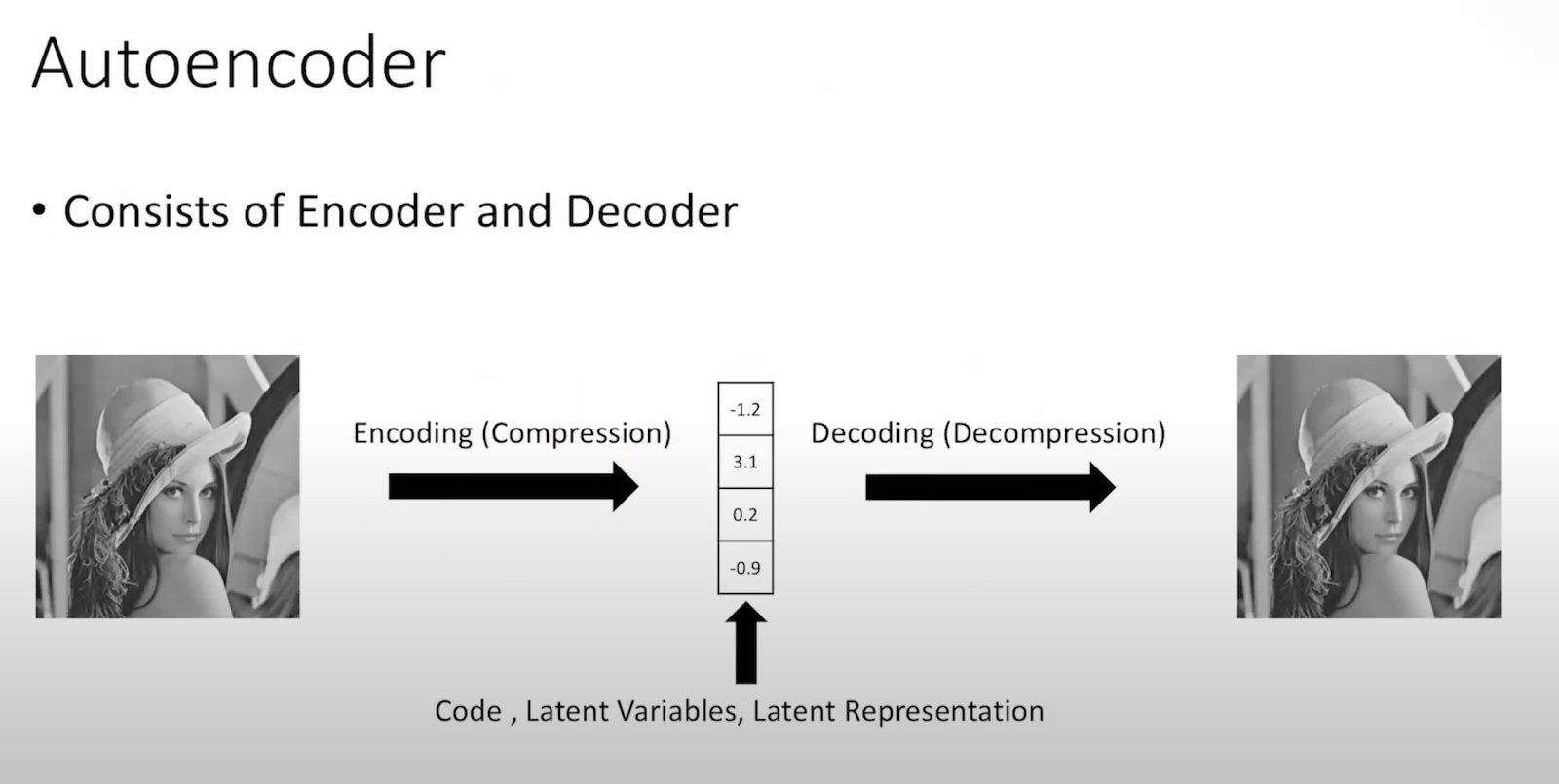
What VAEs want to do is with that space in the middle, sample from it and generate new samples.
But that comes with its challenges.
The idea behind VAEs is that we want to estimate the posterior distribution.

We have X, and we want to know the distribution of Z
But that comes with its challenges.
The idea behind VAEs is that we want to estimate the posterior distribution.
We have X, and we want to know the distribution of Z

So, if we assume that Q is gaussian, we can get the mean and std of that distribution and tune those so we can more closely approximate P(Z|X)
So how do we learn Q(Z) ? We can minimize KL-divergence
Using some log magic we end up with the below.
 In the below formula, logP(X) does not change - that is our data, it is fixed, so what we can do is maximize the ELBO term, this will lead to lowering the KL-divergence. So our job now is to increase the ELBO. In the ELBO term, we know P(Z,X), and from the Q(Z) (which has a gaus dist) we get the mean and std, and we can tune those so that we can maximize the ELBO.
In the below formula, logP(X) does not change - that is our data, it is fixed, so what we can do is maximize the ELBO term, this will lead to lowering the KL-divergence. So our job now is to increase the ELBO. In the ELBO term, we know P(Z,X), and from the Q(Z) (which has a gaus dist) we get the mean and std, and we can tune those so that we can maximize the ELBO.
So, VAE

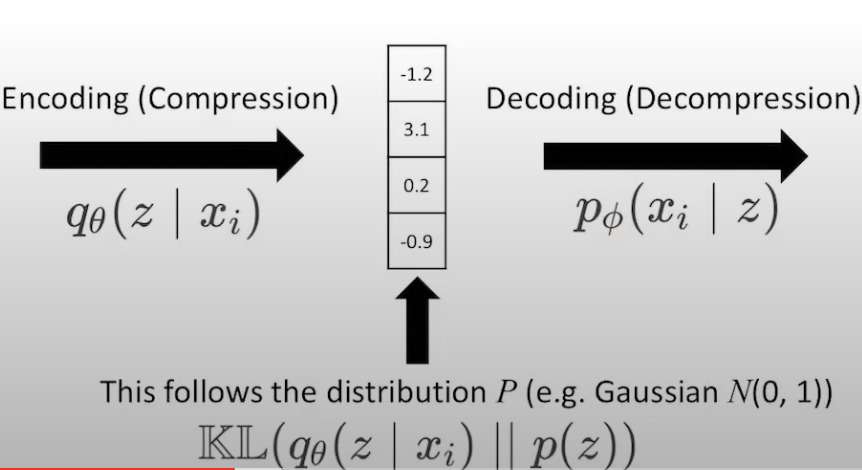
encoder gets X, and generates Z, while the decoder gets Z and generates X
But why do we need the latent space to follow a certain distribution?

How does Loss work ?
In AE, the the X produces Z and then it produces X' and what we do is maximize the ELBO term (tune mu and sigma) to end up with better results. By maximizing the ELBO we minimize the loss. (The ELBO itself can be decomposed into two terms - the reconstruction term and the regularization term (KL-divergence). The reconstruction term measures the reconstruction error of the input data, while the regularization term encourages the latent space distribution to match a predefined prior distribution. By maximizing the ELBO, VAEs encourage the model to learn meaningful latent representations while ensuring that the approximate posterior distribution is close to a predefined prior distribution. The regularization term, enforced by the KL divergence, encourages the latent space distribution to match the predefined prior distribution (typically a gaus dist).

But in VAE the ELBO term is a bit different (with theta and phi).
Side note! it becomes a function of theta and phi (recall earlier 2 pics above that thats what we called the encoder and decoder). In AE, the mean and std are given from X, but here, theta (the encoder) represents a neural network itself and it produces mean and std for each particular sample and using those, we then construct the distribution.
To maximize the ELBO here we can learn theta or phi, but seems that its best to do both. 
How do we train VAEs? Turns out there is a problem

How do we do it then ? By using a so-called 'reparametrization trick'.

I had to double check my notes multiple times and watch the lecture again, so that I can understand the fundamentals. Hopefully I did not make any big mistakes.
2) Implementing a simple VAE
This was a handful, so just to try to understand it a bit more, put the theory to practice I went on youtube and saw VAE from scratch.

The implementation was way easier than the theory behind what is happening haha (as for the loss function, BCELoss was used). But looking at the code, understanding the theory becomes a bit easier.
Now writing this at 1.51am, I realise that the lecture from Professor Choi has practice notebooks, and I checked and it even implements the proper loss (BCE + KLD), but I will go over that quickly tomorrow. I will go to sleep now (zzz)
That is all for today!
See you tomorrow :)

