[Day 46] Meeting Transformers again and their implementation
Hello :)
Today is Day 46!
- Understanding Transformers with Professor Choi from KAIST
The first time I learned about transformer was Day 32, it was a simple intro, but I did not understand exactly what is happening. I felt like, I was just made aware of their existance in the NLP world.

This img is from Andrew Ng's Deep learning course.
In a transformer, the data goes through encoder-decoder network.
In the encoder: for each token its attention is calculated according to the other tokens. And This attention mechanism allows the model to weigh the importance of each token in the context of the entire sequence. This information is put through a feed forward network that extracts deeper features.
In the decoder, we start to predict words. For example we start with an <start of sentence> token, then we pass that at the bottom, then from the encoder we take the K(key) and V(value) and with the Q(query) from the decoder input, we try to predict the next item in the sentence (what word can come after the start of sentence token) - and this happens N amount of times. Also when we do testing, the input to the decoder is masked, we don't give it the whole sentence, because if we do, the model will see the future tokens (words) and 'cheat'.
So... going back and exploring this step by step. (pictures are from Professor Choi's lecture on youtube)
Attention
 if we imagine the the sentence 'I like going to movies', for each word we calculate its attention to the rest of the words in a sentence.
if we imagine the the sentence 'I like going to movies', for each word we calculate its attention to the rest of the words in a sentence.
At the core of doing self-attention is a QKV calculation where Wq, Wk, Wv are learnable params of the model. For each token, to calcualte its attention to itself and others. In a sentence each word (token) gets a turn. Each word, gets its Q, K and V, we calculate the softmax, multiply by the V and we get the sum - Z, which is the attenion (self+to other tokens/words), and we do that computation for each token (word) in the sentence.
 We give input tokens, in the self-attention QKV is done, we get the Z ouput, which we put through a FFN that is basically linear layers that learn information, and then that output is passed into the next encoder block, which does the same.
We give input tokens, in the self-attention QKV is done, we get the Z ouput, which we put through a FFN that is basically linear layers that learn information, and then that output is passed into the next encoder block, which does the same.
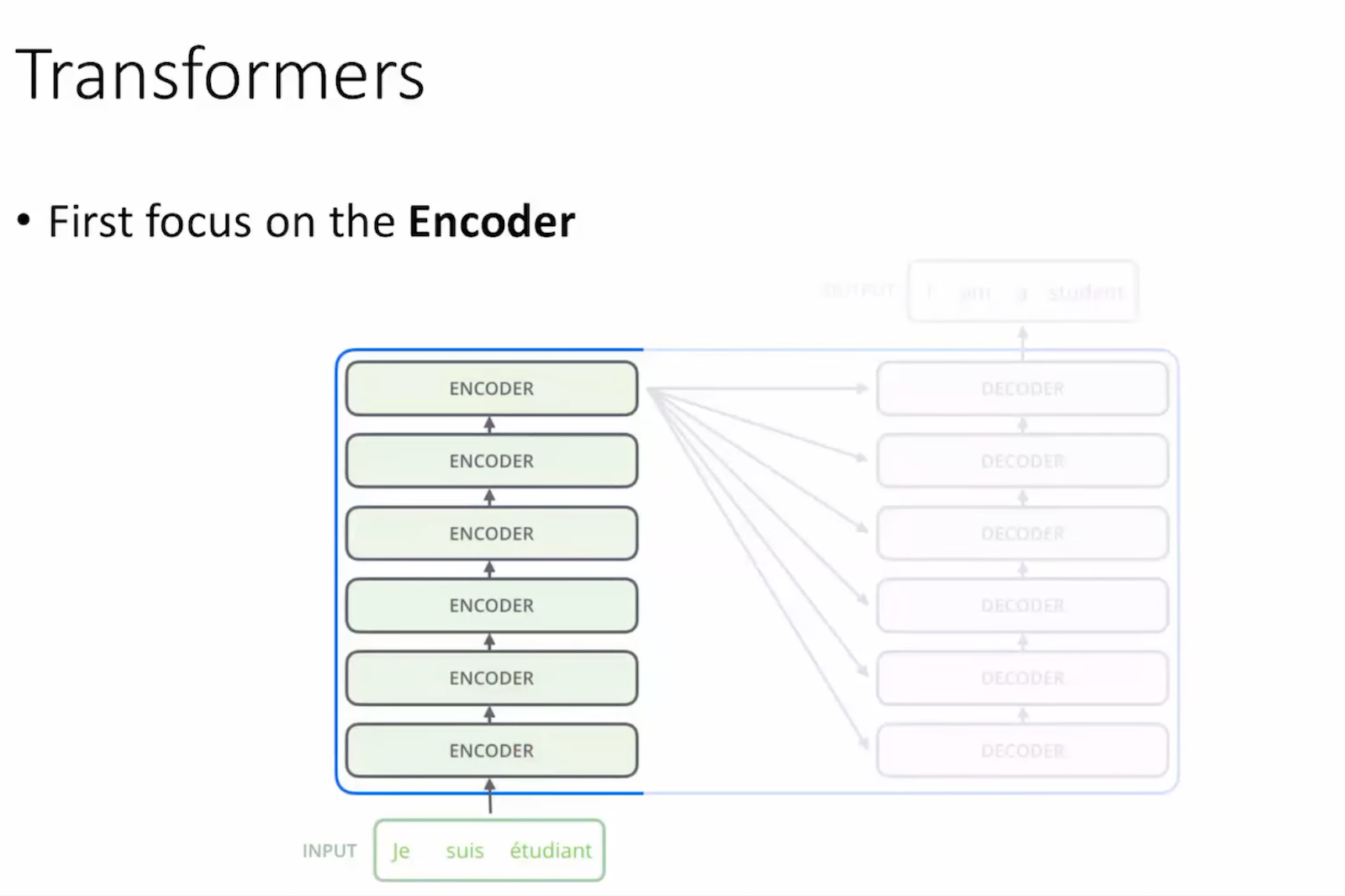 A sample Encoder layout ^
A sample Encoder layout ^ encoders do not have idea of the order. If we take an example sentence: you are a boy vs are you a boy - the order matters and it changes the sentence. Since the encoder doesn't know what is the order, if a sentence was "I like banana and like" - the word like will get the same attention scores, but that would be wrong, because the 2nd like - we can tell it is a mistake, so the encoder should learn and know how to order a sentence.
encoders do not have idea of the order. If we take an example sentence: you are a boy vs are you a boy - the order matters and it changes the sentence. Since the encoder doesn't know what is the order, if a sentence was "I like banana and like" - the word like will get the same attention scores, but that would be wrong, because the 2nd like - we can tell it is a mistake, so the encoder should learn and know how to order a sentence. We pass the tokens to the self-attention computation (QKV), but before that we make sure to add positional encoding, so the encoder can know the order of a sentence. Then the outpuz of the self-attention is added with the pre-self-attention vector, and then is normalized, AND THEN it is passed to the FFN, which again is normalized and has residuals added.
We pass the tokens to the self-attention computation (QKV), but before that we make sure to add positional encoding, so the encoder can know the order of a sentence. Then the outpuz of the self-attention is added with the pre-self-attention vector, and then is normalized, AND THEN it is passed to the FFN, which again is normalized and has residuals added.  When the decoder works, it generates the Q(query) from the current structure that it has (image we have a stard of sentence and I tokens), so it generates the Q based on that, next - it takes the K, V we learned in the encoder, so that the decoder can learn what is the best next word to generate.
When the decoder works, it generates the Q(query) from the current structure that it has (image we have a stard of sentence and I tokens), so it generates the Q based on that, next - it takes the K, V we learned in the encoder, so that the decoder can learn what is the best next word to generate.
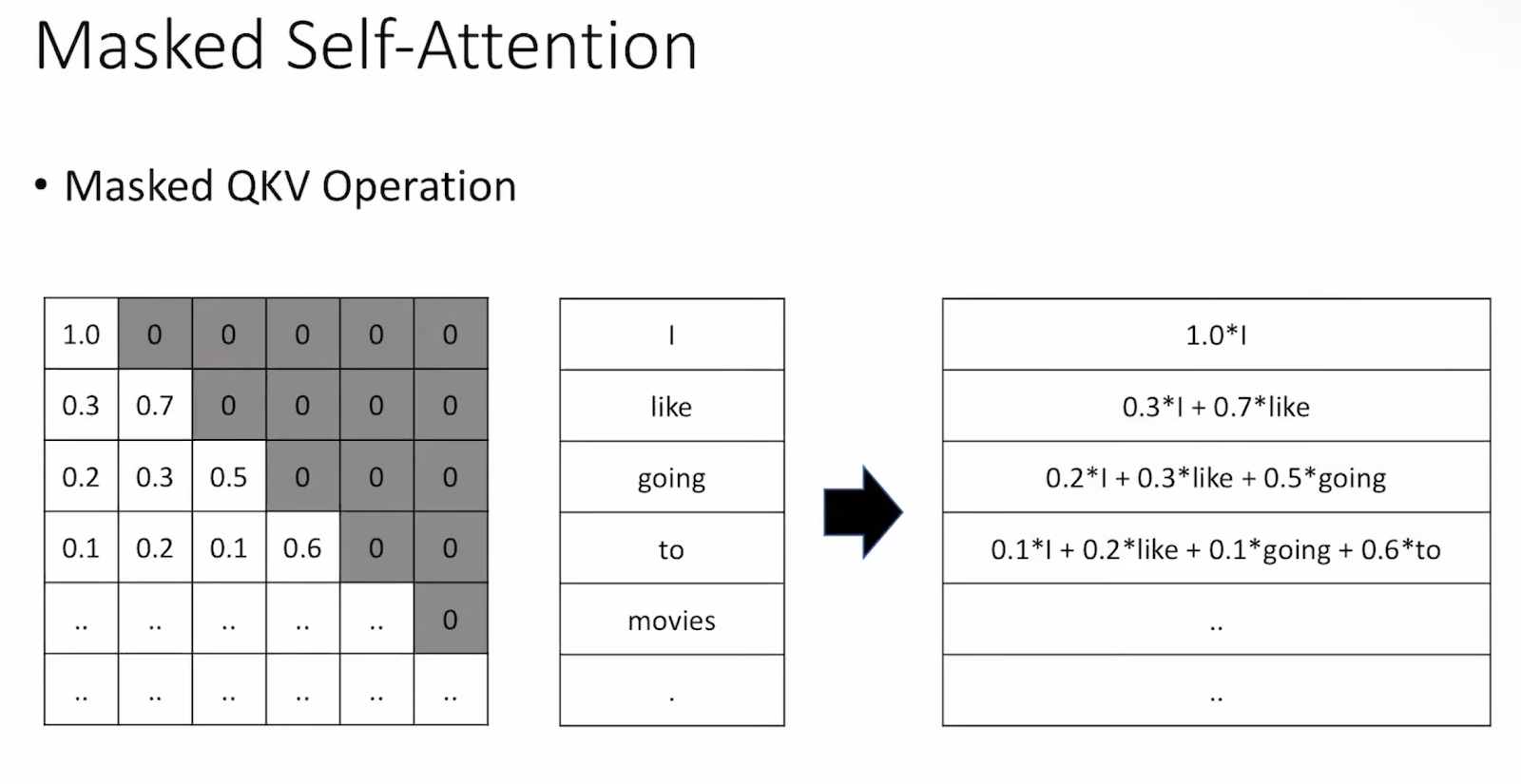
In the decoder there is also masking. But why ? Why masked self-attention?
 The decoder generates word by word, so in order to do that we want to mask the future tokens of a sentence, so that the generator does not cheat and look at them.
The decoder generates word by word, so in order to do that we want to mask the future tokens of a sentence, so that the generator does not cheat and look at them.  So if we have <sos>, I and am tokens, we will hide the next tokens (in this example a and student), so that the decoder does not cheat. We ensures that the model learns to predict tokens based only on the information available at the time of prediction.
So if we have <sos>, I and am tokens, we will hide the next tokens (in this example a and student), so that the decoder does not cheat. We ensures that the model learns to predict tokens based only on the information available at the time of prediction.
At the core of doing self-attention is a QKV calculation where Wq, Wk, Wv are learnable params of the model. For each token, to calcualte its attention to itself and others. In a sentence each word (token) gets a turn. Each word, gets its Q, K and V, we calculate the softmax, multiply by the V and we get the sum - Z, which is the attenion (self+to other tokens/words), and we do that computation for each token (word) in the sentence.


So... we get the Z values, now the structure of a sample encoder block is:
Inside the encoder block we have a few more calculations. But before that, there is an important point - positional encoding.
So,
Next, the decoder takes info from the encoder and tries to generate output. The decoder's structure is as below.
In the decoder there is also masking. But why ? Why masked self-attention?
We do this masking by a triangular matrix multiplication
(below, we do -inf there to ensure that the output of the softmax will sum to 1 and also that the values are actually 0. If the upper right corner is 0 and not -inf, what we will get in the output masked QKV operation is not 0s but small numbers instead)

To sum up, this slide nicely says what is happening when we generate text.
We start with the <sos/start> token, get the Q - which represents the decoder's current state and is used to attend to the encoder's output. Then using the K and V with the encoder, we get the attention scores at the current stage, and we end up with a list of values, and based on softmax, we have a list of probabilities of which word may follow.

If we look at the overall structure of a transformer


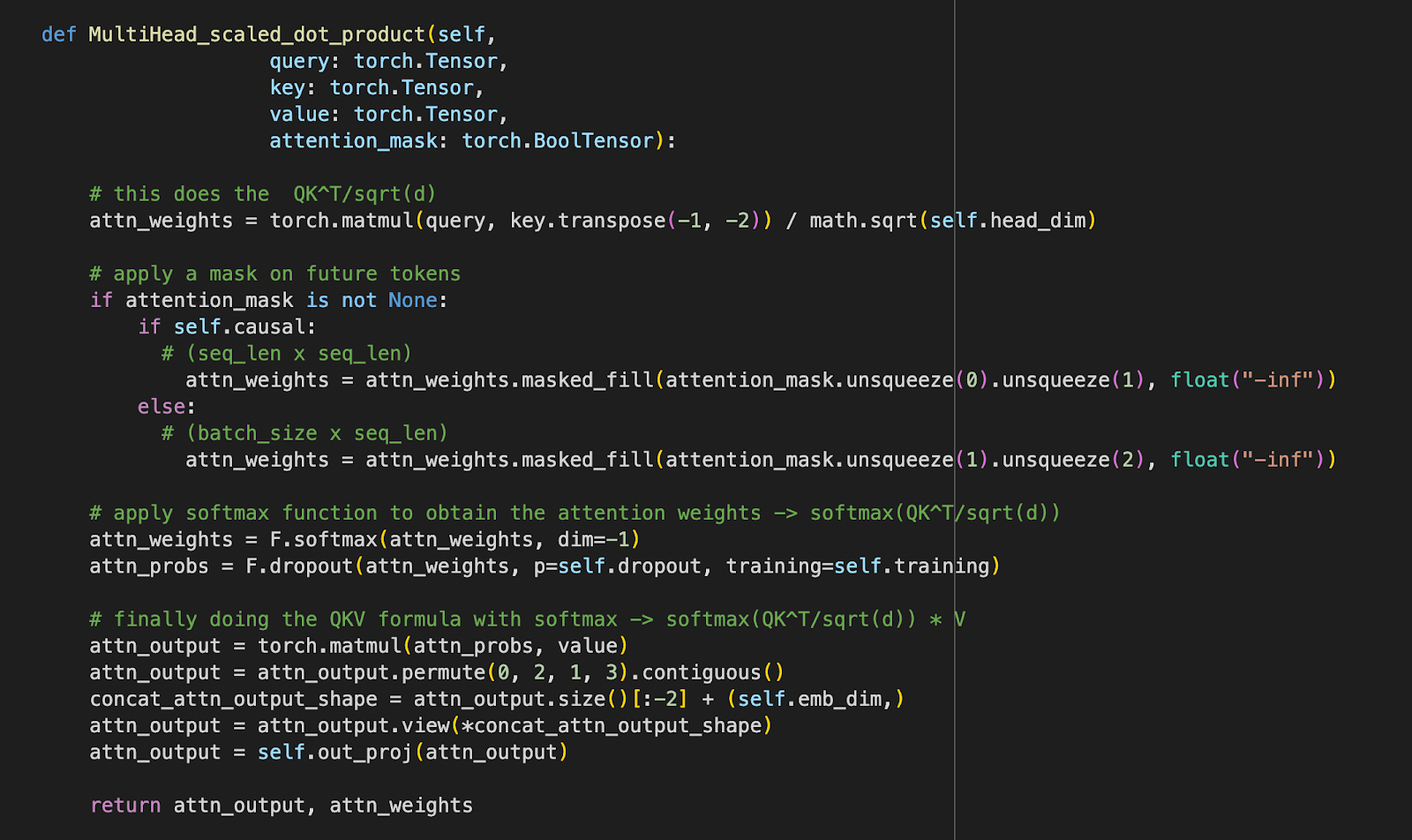

Today was a handul as well haha. But this knowledge is crucial for my general understanding of what is popular in the field these days (i.e GPT models).
That is all for today :)
See you tomorrow

