[Day 57] Stanford CS224N - Lecture 1. Word vectors
Hello :)
Today is Day 57!
Quick summary of today:- Got introduced to word vectors with lecture 1 + small showcase
- Read the paper and took notes about:
First I watched the lecture by Professor Manning, and then I read the papers so some of the material was overlapping, but there were still interesting new parts in each of the three.
1) Lecture notes
My notes from the lecture were not that long so I will first share them.










2) word2vec paper summary
1. Intro
Before word2vec, many nlp systems treated words as single units that do not have any notion of similarity. while this provided simplicity and robustness, such techniques had limits. for instance higher volume of data resulted in good performance, but if big data was not available, the models had limitations. Data was the limitation. but with the progress of ML, the newer and more complex models could be trained on larger data and outperform the simpler ones.
They used a, back then, recent technique for word representation that not only puts similar words closer to each other, but also words can have multiple degrees of similarity.
2. Popular neural network models
- Feedforward Neural Net Language Model (NNLM)
- Recurrent Neural Net Language Model (RNNLM)
- Continuous Bag-of-Words CBOW Model

- Continuous Skip-gram Model

4. Results
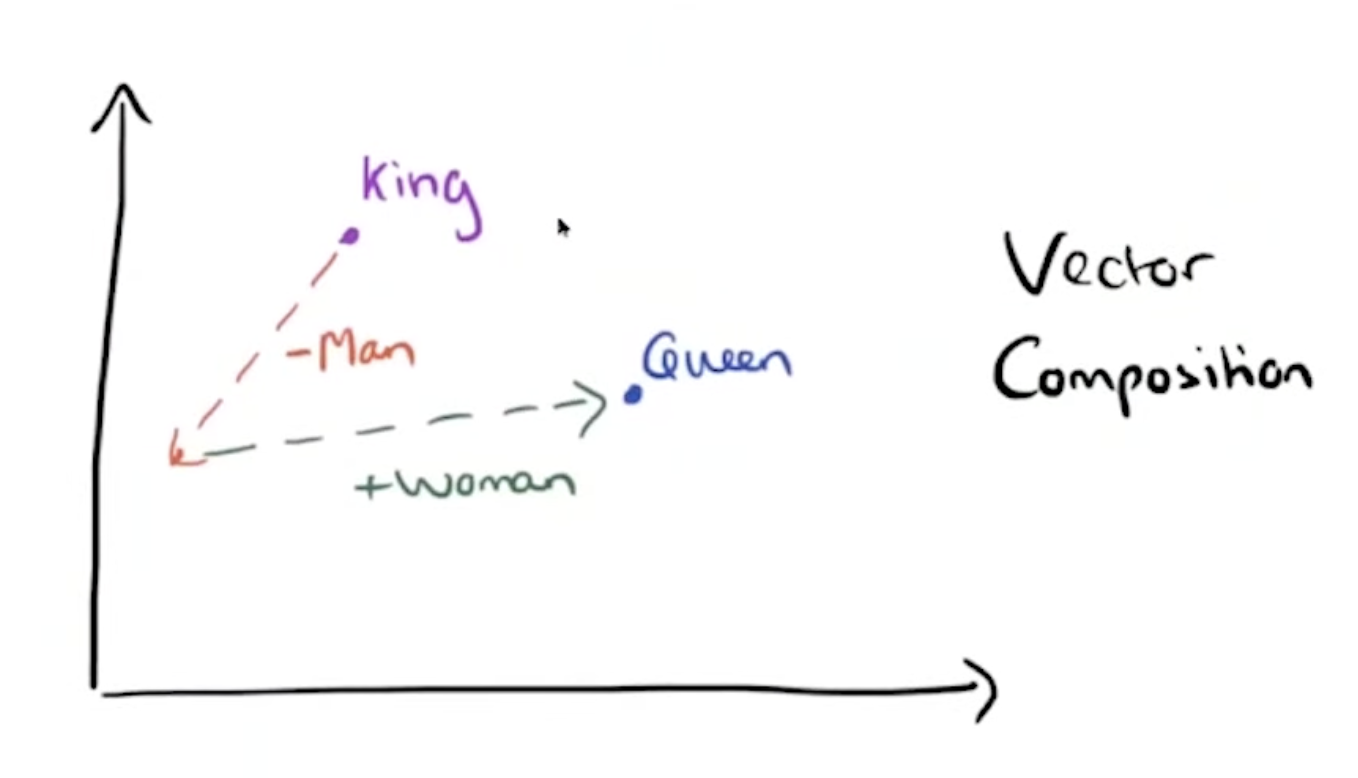
To show results, they proposed to use analogies, for example big is to bigger is as small is to ____? And they found that such questions can be answered with algebraic operations with the vector representation of words.
X = vector(‘bigger’) - vector(‘big’) + vector(‘small’), then from the vector space a word that is closes to X (measured by cosine distance) is given as the answer. They evaluated the accuracy of the model and assumed a correct answer only if the closest word to the vector computed is exactly the same as the correct word in the question. For instance, if the model is given the pair (king, queen) the correct word that the model should predict as closest might be "queen”. (more pairs in the 1st pic below)


3) negative sampling paper
1. Intro
Distributed representations of words in a vector space helps learning algorithms to achieve better performance in NLP tasks by grouping similar words. Compared to, back then, other models, the skip gram model we saw in the 1st paper, does not invlove matrix multiplication into its training process which makes that process very efficient and a singple machine implementation can train on more than 100 billion words in 1 day. In this paper, the researchers propose that subsampling of frequent words during training results in a significant speedup and improves accuracy of the representations of less frequent words. They also propose a simplified variant of Noise Constrastive Estimation (technique that involves distinguishing between true data and noise samples) for training the skip-gram model which comes with better results compared to the originally used hierarchical softmax.
2. The skip-gram model
Its goal is to find word representations that are useful for predicting the context around a word/document. To achieve this, the model aims to max the avg log probability:

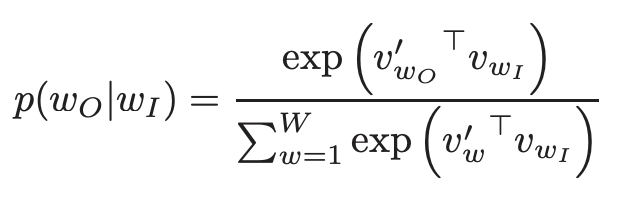
To overcome that, a computationally efficient approximation of the full softmax is called the hierarchical softmax. And its main advantage is that instead of evaluating W output nodes in the NN to obtain the probability distribution, it only needs to evaluate log2(W) nodes.
4. Subsampling of frequent words
In a very large body of text, words like “the”, “a”, “in” can occur millions of times, and they provide less value compared to the rarer words. For example the words France and Paris are helpful to the skip-gram model, but the occurance of France and the togehter right next to each other will be most likely higher. To deal with this imbalance of words, they used a sub-samping approach where each word Wi in the training data is discarded with a probability:

5. Evaluation
To evaluate Hierarchical softmax (HS), Noise contrastive estimation (NCE), negative sampling (NGE) and subsampling of the training words, they used the same small:smaller = big: ? method as the word2vec paper. And the results are:

Many words cannot be explain just by learning the meaning of individual words - such as New York Times. To tackle this, they find words that appear frequantly together and infrrequentyl in other contexts, and such phrases are replaced by unique tokens. But cases like “this is” remains as is. After doing so, the analogy method was used again for evaluation. Results:

Looking forward to the next lecture tomorrow :)
That is all for today!
See you tomorrow :)

