[Day 219] Fundamentals of Data Eng and LLM data preprocessing pipelines in Mage
Hello :)
Today is Day 219!
A quick summary of today:- starting 'Fundamentals of Data Engineering'
- covered module 5: orchestration of the LLM zoomcamp

The Data Engineering Lifecycle

Rather than fixating on the tech, this book focuses on the ideas and thinking behind the tech and the processes in the data's lifecycle. It summarises the lifecycle stages as:
- generation
- storage
- ingestion
- transformation
- serving
The early days: 1980 to 2000, from data warehousing to the web
Data engineering's roots lie in the development of data warehousing in the 1980s, spearheaded by innovations such as relational databases and SQL. The rise of the internet in the mid-1990s necessitated robust data systems for emerging web-first companies, leading to the evolution of scalable analytics and roles focused on data warehousing and business intelligence.
The early 2000s: The birth of contemporary data engineering
Post-dot-com bust, surviving tech companies like Yahoo, Google, and Amazon pushed traditional data systems to their limits, necessitating scalable, cost-effective solutions. This period saw the advent of big data, driven by innovations like Google's MapReduce and the emergence of Hadoop, along with the rise of public cloud services such as AWS, which revolutionized data storage and computing
The 2000s and 2010s: Big data engineering
The birth of open-source big data tools and the transition to real-time data streaming defined this era. Hadoop and its ecosystem enabled companies to handle massive data sets, although the hype around "big data" sometimes led to its misapplication. The focus shifted from maintaining complex infrastructures to delivering business insights, paving the way for today's data engineering practices.
The 2020s: Engineering for the data lifecycle
Data engineering has evolved towards modular, managed, and highly abstracted tools, forming the modern data stack. The role now emphasizes data lifecycle management, including security, governance, and compliance, while leveraging improved tools and techniques to handle diverse and growing data sources efficiently. This period marks a golden age of data management, focusing on agility and decentralization
Data Engineering and Data Science
There is some debate, but like I thought, the writers believe that DS is a downstream task of DE



Data Engineering Skills and Activities
Data engineers used to focus on managing complex, monolithic technologies and low-level details, but now they utilize modern, simplified tools to create agile, cost-effective data solutions. They do not typically build ML models, create reports, perform data analysis, or develop software, though they must understand these areas to support stakeholders.Data Maturity and the Data Engineer
The level of data engineering complexity within a company depends a great deal on the company’s data maturity. This significantly impacts a data engineer’s day-to-day job responsibilities.
Data maturity is the progression toward higher data utilization, capabilities, and integration across the organization, but data maturity does not simply depend on the age or revenue of a company.

Stage 1: Starting with Data
- Characteristics: Early data maturity, vague goals, nascent data architecture, low adoption, small data team
- Data Engineer's Role: Generalist, aiming to move quickly and add value
- Challenges: Avoid premature ML projects, prevent working in silos, and steer clear of unnecessary complexity
- Characteristics: Transition from ad hoc data requests to formal practices, scaling architectures
- Data Engineer's Role: Specialist, focusing on scalable, robust architectures and formal practices
- Challenges: Avoid chasing bleeding-edge tech, focus on practical solutions, and lead pragmatic data initiatives
Stage 3: Leading with Data
- Characteristics: Data-driven company with automated pipelines, self-service analytics, seamless data introduction
- Data Engineer's Role: Deep specialist, ensuring data availability and leveraging data for competitive advantage
- Challenges: Avoid complacency, prevent technology distractions, and focus on business value
- Know how to communicate with nontechnical and technical people
- Understand how to scope and gather business and product requirements
- Understand the cultural foundations of Agile, DevOps, and DataOps
- Control costs
- Learn continuously
A data engineer should know how to code and possess production-grade software engineering skills. Although managed services and SaaS have simplified some tasks, strong coding abilities and understanding of software engineering best practices are still crucial for handling complex technical needs and gaining a competitive edge.
Main languages: SQL, Python, Java, Scala, bash
Secondary languages: R, JavaScript, Go, Rust, C/C++, C#, and Julia
How do you keep your skills sharp in a rapidly changing field like data engineering?
Focus on the fundamentals to understand what’s not going to change; pay attention to ongoing developments to know where the field is going. New paradigms and practices are introduced all the time, and it’s incumbent on you to stay current. Strive to understand how new technologies will be helpful in the lifecycle.
The Continuum of Data Engineering Roles, from A to B
In Data Science there are type A and type B data scientists - Analysis (understanding and deriving value from data), and Building (building systems that work in production, while sharing skills with type A).
In DE, there are type A and B engineers too.
Type A data engineers
A stands for abstraction. In this case, the data engineer avoids undifferentiated heavy lifting, keeping data architecture as abstract and straightforward as possible and not reinventing the wheel. Type A data engineers manage the data engineering lifecycle mainly by using entirely off-the-shelf products, managed services, and tools. Type A data engineers work at companies across industries and at all levels of data maturity.
Type B data engineers
B stands for build. Type B data engineers build data tools and systems that scale and leverage a company’s core competency and competitive advantage. In the data maturity range, a type B data engineer is more commonly found at companies in stage 2 and 3 (scaling and leading with data), or when an initial data use case is so unique and mission-critical that custom data tools are required to get started.
It can be different people or 1 person that performs both.
Data Engineers Inside an Organization

An external-facing data engineer designs and manages systems for collecting, storing, and processing data from user-facing applications like social media, IoT devices, and e-commerce platforms. These systems face challenges such as high concurrency, query limits to manage infrastructure impact, and complex security issues, especially with multitenant data.

An internal-facing data engineer typically focuses on activities crucial to the needs of the business and internal stakeholders. Examples include creating and maintaining data pipelines and data warehouses for BI dashboards, reports, business processes, data science, and ML models.
How Data Engineers Interact with Other Roles

Next, Module 5: Orchestration of the LLM zoomcamp
In mage, there is a new pipeline type for RAG apps:

The first data prep stage includes:
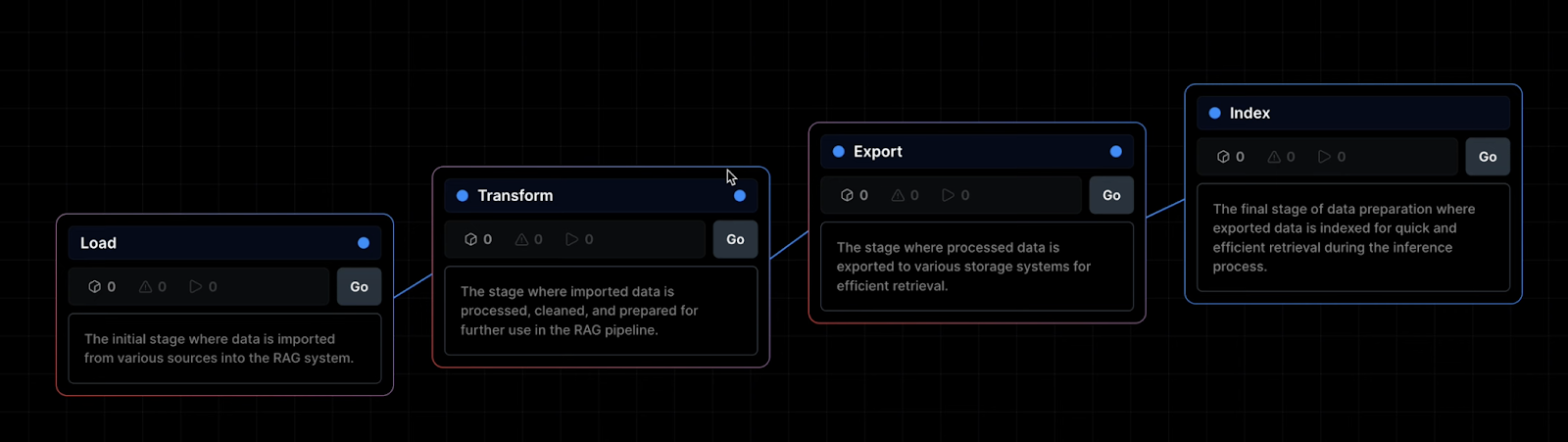
To be honest, just like with the original MLOps zoomcamp videos that introduce mage, these videos seemed rushed and do not explain much while there being a lot of moving pieces in the UI. In total it is 8 videos, each ~2 minutes. Seems that this RAG pipeline will be part of Mage Pro (a paid version) so I will try not to be too attached to it as I doubt I am going to pay to use Mage. Nevertheless, I might end up using this feature for my LLM zoomcamp project. Or I might just go with a normal pipeline with normal blocks.
That is all for today!
See you tomorrow :)

