[Day 215] Trying out 'traditional' models on the KB project transaction fraud data
Hello :)
Today is Day 215!
A quick summary of today:- trying out different models to classify non fraud/fraud transactions
In addition to the Graph Convolutional Network model, I wanted to create some 'traditional' (non-neural net) models for better comparison and judgement.
The features I used for the below models are:
numerical: amt (amount)
categorical: category, merchant, city, state, job, trans_hour, trans_dow
Then I downsampled the majority class (non fraud cases; just like for the GCN model).
Logistic Regression

CatBoost

Best params: {'depth': 6, 'iterations': 300, 'learning_rate': 0.3}
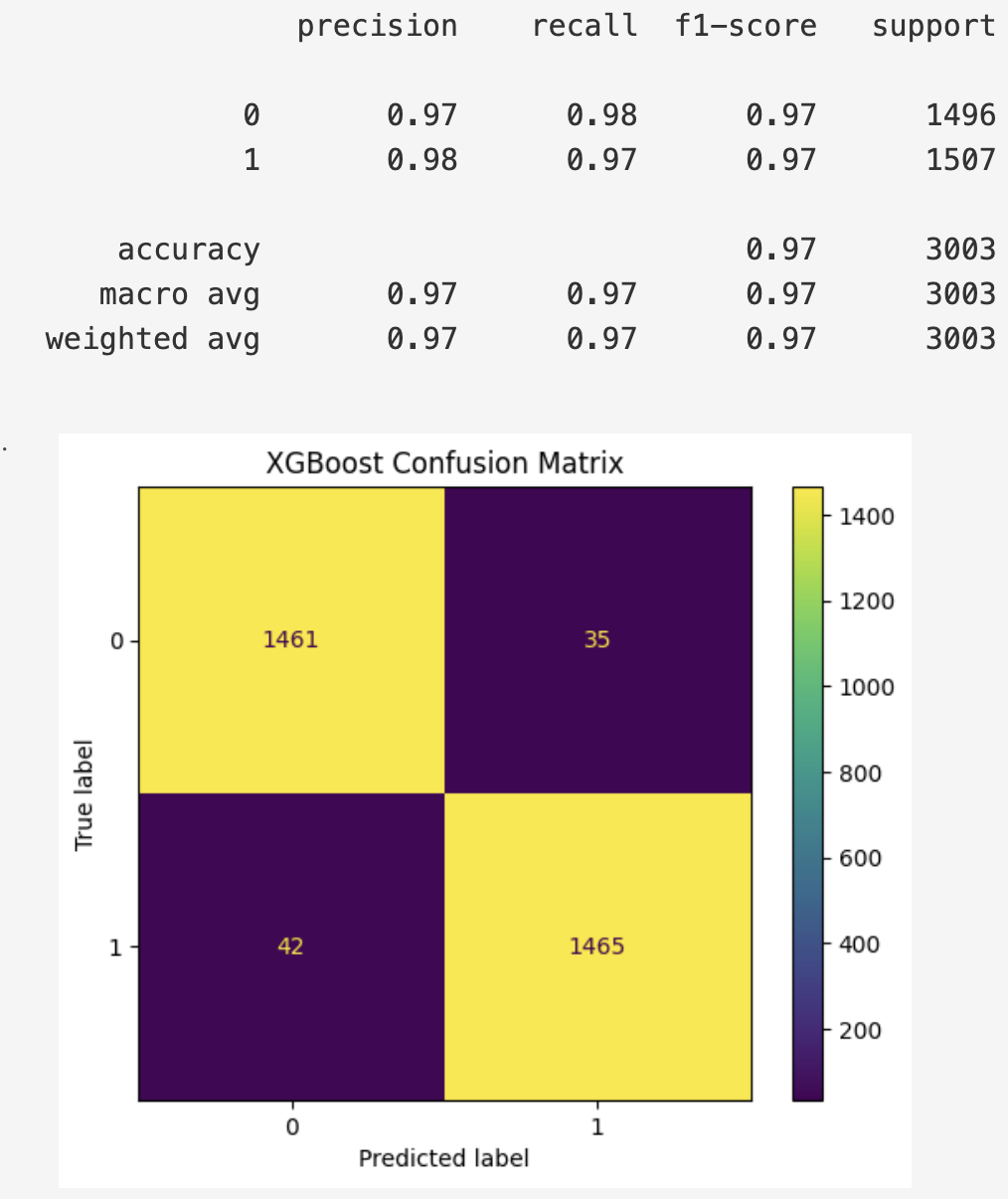
XGBoost
RandomForest

LGBMClassifier

Among the top, XGBoost and CatBoost seem to perform the best, and for tomorrow I will add them to individual Mage training pipelines, and then in the Mage inference pipeline. The idea is that having different models' predictions on a transaction can help with decision making and also that kind of info can be shown in Grafana as well. What is more from these models, we can get feature importance, and even SHAP values to better understand their decision making.
That is all for today!
See you tomorrow :)

