Hello :)
Today is Day 209!
A quick summary of today:- creating Mage pipelines for the KB AI competition project
The repo after today
Today morning/afternoon I went on a bit of a roll ~
I set up all the above pipelines in Mage. Below I will go over each one
get_kaggle_data
it is just one block that downloads the data for the project from
Kaggle using the kaggle python package
load_batch_into_neo4j
Gets the loaded data from the get_kaggle_data pipeline and inserts it into neo4j. This is the fraudTrain.csv from the Kaggle website (because the fraudTest.csv will be used for the pseudo-streaming pipeline).
train_gcn
I tried to split this into more blocks, but at the moment the way I structured the code, the most optimal solution was to do it all at once. That is - create a torch-geometric dataset, create node and edge index, train the model, test it, and save summary info. At the moment, because everything is local, I am using mlflow just for easy comparison but later (after the project submission) I will add a proper mlflow server with a cloud db and artifact store where I can save models, and from where I can load models and other data.
When this pipe is run, locally and in mlflow such folder is created:
Here are the images/text from this model run:
Confusion matrix:
Feature importance (I need to modify this because besides 5 of the vars, the other are categorical dummies and I need to add a suffix to make it clear):
Accuracy: 0.8809, Precision: 0.8133, Recall: 0.9883, F1: 0.8923
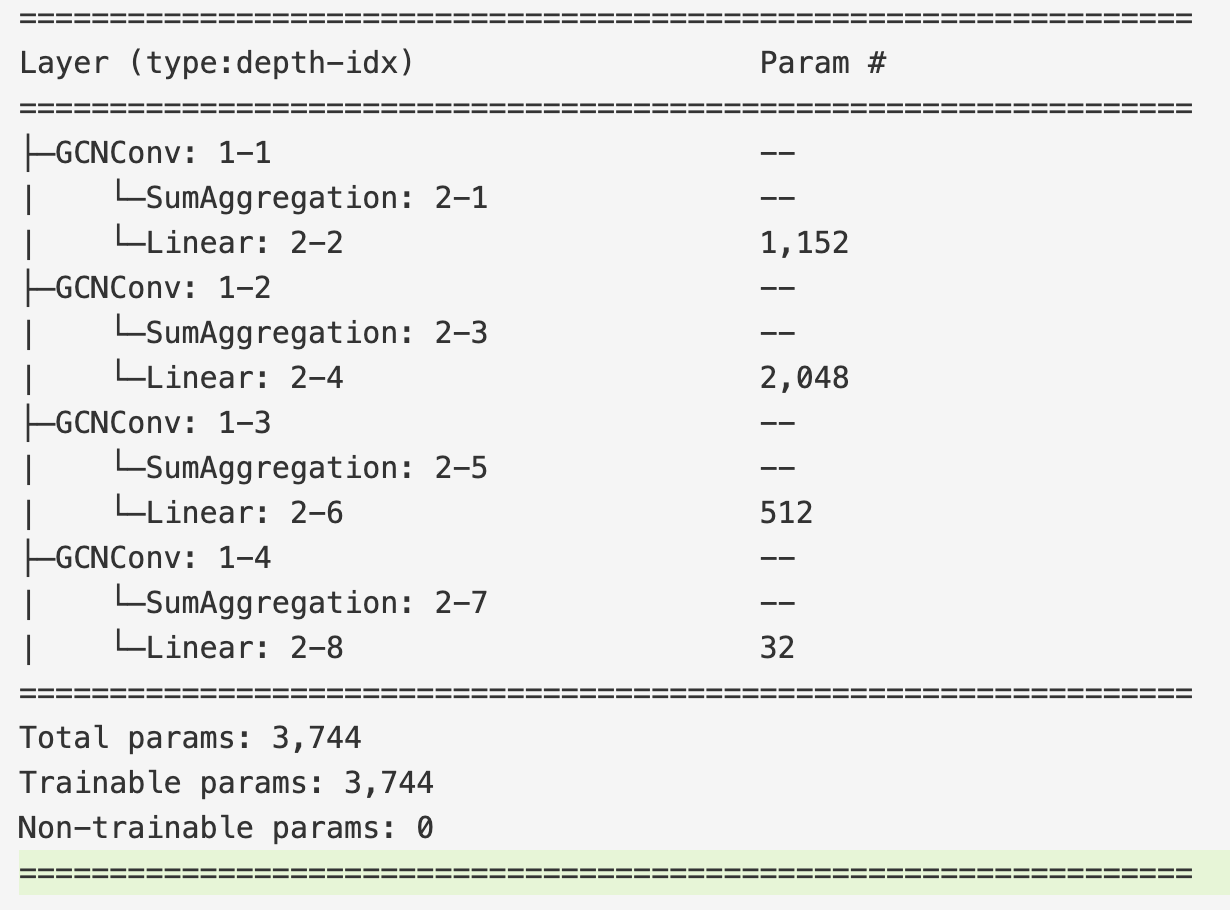
Model summary:
stream_predictions
For this pipeline to work I needed to set up a kafka producer to send data to the kafka stream. I created this and shared it in yesterday's post.
Mage has a nice setup for streaming pipelines. The 1st block establishes a connect to read data from the kafka stream (to which I am sending transactions). In the 2nd block, using the data from the stream, I create a Data object that can be used as input to the trained GCN, and add it to the message:
And in the final block - insert the new data to neo4j.
Another thing - creating a simple model dictionary using streamlitTo create it I added a new option to the Makefile. Yesterday I thought I would use docker to create a service, but because I am not using mlflow with a proper db and artifact store, if I want to load images/text (as the above confusion matrix, model summary, etc.) I need to upload those files to the streamlit docker image as well, and this seems unnecessary. Once mlflow is set up properly then using streamlit from docker might be a viable choice.
As for how the streamlit model dictionary looks:
it includes all the model info that is produced from the train_gcn pipeline.
And once we have other models, their info can easily be added.
That is all for today!
See you tomorrow :)