Day 192] Chapter 4: Scaling with the compute layer (from the book: Effective Data Science Infrastructure)
Hello :)
Today is Day 192!
A quick summary of today:- set up AWS resources and configured metaflow with aws (finally)
What is Scalability?
Scalability refers to a system's ability to handle increasing amounts of work by adding resources. This concept is distinct from performance, which measures how well a system functions under a fixed workload. Scalability involves:
1. Growth: It’s relevant only when discussing systems that need to handle more work.
2. Efficient Resource Use: Adding resources like more computers or memory should proportionally increase the system's capacity.
3. Different Measures: The dimensions of scalability (e.g., volume, velocity, validity, and variety) must be defined based on specific needs.
When building infrastructure, it’s crucial to ensure scalability across all layers, supporting a large number of applications and users, and enabling quick development and deployment of data science projects.
Culture of Experimentation
Modern data science organizations should allow data scientists to innovate freely without being limited by compute resources. This is facilitated by the reduced cost of computing, particularly through cloud infrastructure, which offers near-unlimited resources.
However, as organizations scale, communication overhead can become a significant issue. Traditional hierarchical structures limit this overhead but modern organizations prefer more flexible, less hierarchical models. Effective use of cloud resources can minimize the need for coordination by providing easy access to computing power, thus supporting more projects and enabling more experimentation
Key Strategies for Scalability:
1. Minimize Interference: Ensure that different workloads do not negatively impact each other. This can be achieved through:
- Proper isolation of workloads.
- Using modern cloud infrastructures and container management systems.
- Employing versioning, namespaces, and dependency management.
2. Enable Autonomy: Allow data scientists to manage the entire prototyping and deployment process independently, reducing the need for extensive coordination.
In summary, scalability is about efficiently handling growth by leveraging additional resources, while minimizing the need for coordination and ensuring system robustness. This fosters a productive environment where data scientists can experiment and innovate freely.
Next, the compute layer
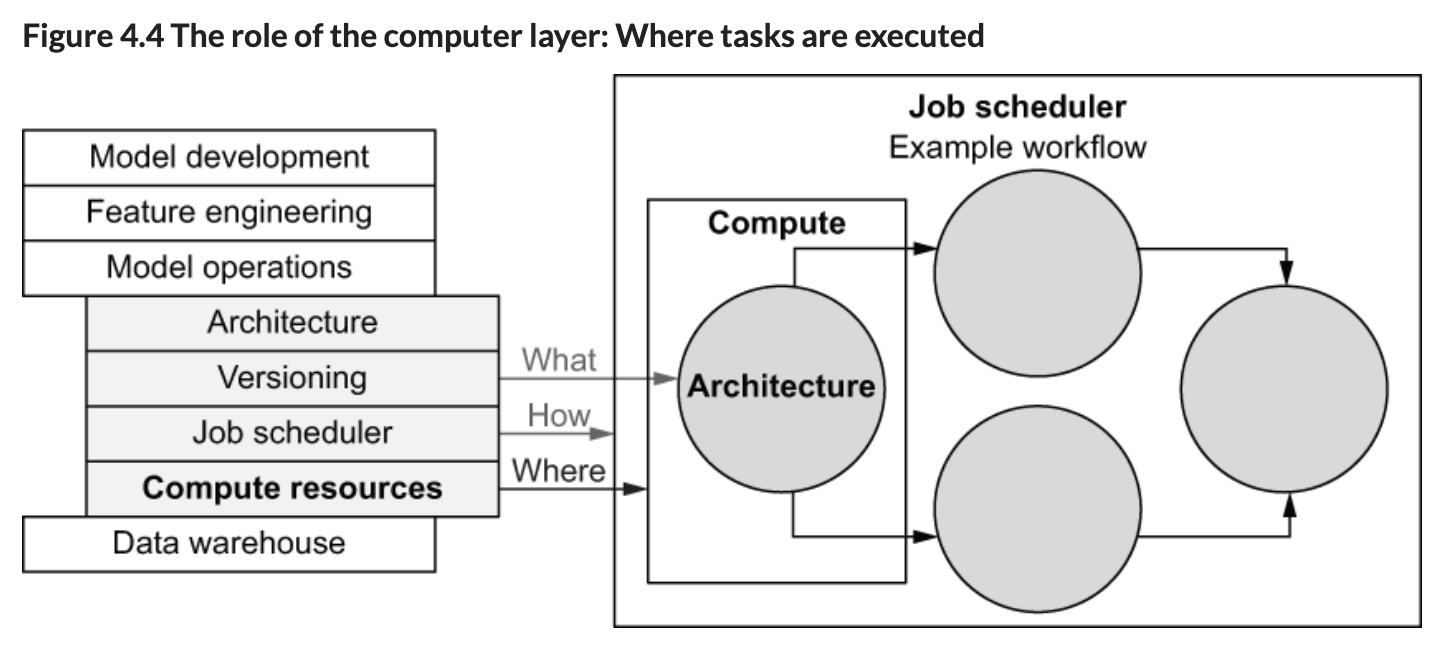
Infrastructure Stack and Workflow Execution:
- Workflow Interface: Users define tasks via workflows, but the compute layer only handles individual tasks.
- Workflow Orchestrator: Schedules tasks and determines execution timing.
- Compute Layer: Focuses on where to execute tasks, based on resource requirements (CPUs, RAM).
Compute Layer Requirements:
- Must handle numerous concurrent tasks.
- Manages a dynamic pool of physical computers.
- Efficiently matches tasks to available resources, a complex problem (Bin Packing, Knapsack problem).
- Ensures robustness against failures and errors.
Evolution with Public Clouds:
- Public clouds like AWS have simplified building scalable, robust compute layers.
- They allow elastic scaling from small to supercomputer levels, paying only for usage.
- However, the basic cloud interfaces are low-level and require additional architectural decisions for data science workloads.
Diverse Compute Needs:
- Different applications have varying compute requirements.
- Data science infrastructure should support various compute layers (local laptops, cloud workstations, GPU clusters).
- These layers can share a common interface and architecture to manage diversity effectively.

- Instance Pool: Contains computers that run containers executing user code.
- Cluster Management System: Manages the instance pool, adding or removing instances based on demand and health, accommodating diverse hardware configurations.
- Container Orchestration System: Queues pending tasks and assigns them to suitable instances based on resource requirements, ensuring tasks are placed on available instances with the necessary resources (e.g., GPU).
Examples of compute layers

- workload support
- latency
- workload management
- cost-efficiency
- operational complexity
- kubernetes
- AWS Batch
- AWS Lambda
- Apache Spark

Cost?
To optimize cloud-based compute costs, companies should maximize utilization, ensuring instances perform useful work as much as possible. This can be achieved by shutting down idle instances and sharing instances across multiple projects to avoid downtime. While instances are cheaper than data scientists, using more instance hours to save data scientist time can be more cost-effective, even if the code is inefficient.

Configuring mlflow with aws
The book did not provide *exact* way to do it but it pointed me towards a resource that can help. TLDR - I set up resources in AWS using this CloudFormation template and then configured metaflow to connect to them.
Now when I run a task locally it goes to AWS, and I see something like:

@resources
This decorator specifies the resources allocated to a step, such as CPUs and memory, typically used for local or Kubernetes execution.
@catch
This decorator handles exceptions for a step, specifying what should be done if the step fails.
To see the decorators in action, I used some basic flows. All the code from today is in the chapter 4 directory in my repo.
Looking forward to chapter 5: Practicing scalability and performance
That is all for today!
See you tomorrow :)