[Day 188] Setting up automatically updated monitoring UI using streamlit
Hello :)
Today is Day 188!
A quick summary of today:- setting up postgres properly
- creating and hosting a monitoring interface using streamlit
- creating a Grafana dashboard
- setting up a batch model prediction flow in prefect
All code from previous days and today is on my repo.
First, setting up a better way to upload data to postgres
Before, everytime I ran docker the script checked if I had inserted data into postgres. Now I set up a proper sql script that inserts data once and I am set up (as long as I do not delete the built container of course)
I put all the sql and commands I used to upload the data in the postgres folder in my repo.
I first create the tables (pic is truncated)

I uploaded 2 datasets to postgres - the above one, and one ready for the balanced random forest classifier model - it is the same as the above one but all vars are in dummies. Given that, I removed all instances in my code where I read data from local sources -> now every instance reads code from the database.
Second, onto monitoring
I cleaned up the monitoring folder - removed LIME as I am not going to use it for this project, and I decided to use streamlit to automate the monitoring UI generation and serving.
And it is here. I figured out how to render the html reports generated by Evidently, and also added SHAP images. Luckily for me, recently streamlit introduced pages - so the UI looks nice.




Next, I created a prefect flow that updates the artifacts (html and png files) used for the monitoring UI, and after the user uploads them to github -> the streamlit UI will be updated as well. A nice little automation piece.
Next, I decided to use Grafana to create some kind of a visualisation dashboard there.
I set up a connection to postgres to read data, and after some playing around, I created a basic dashboard. It is quite similar to Looker.
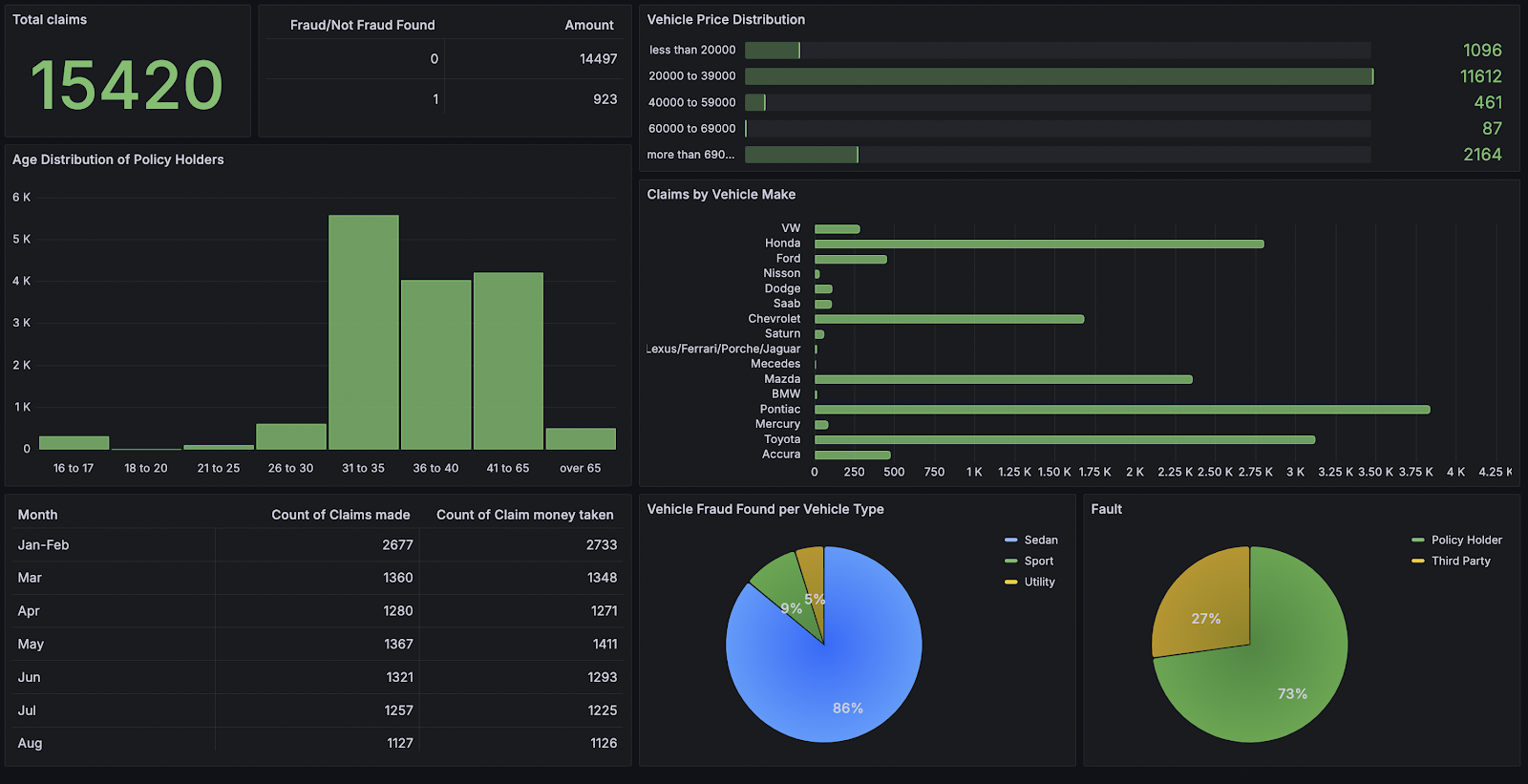
Rather than streaming - i.e. something that users input single data points and get an output, this type of model might be better suited for batch - use a new whole dataset and predict Fraud/Not Fraud for the whole thing.
If I decide to (just for fun) do a web server using FastAPI, I found this nice video which shows how to host a FastAPI app for free.
Then, I just created a prefect flow that takes in new data, the model to use, adds prediction column (and optionally preds probabilities), and finally uploads it to postgres.
I have five prefect flows at the moment ^^

I am thinking now about adding tests, maybe creating a python documentation with sphinx since I added simple docstrings to all my code and data types. But those are tasks for tomorrow/next days.
I need to add terraform as well so that the GCP infrastructure is initialised using terraform, rather than manually (a bit more automation).
That is all for today!
See you tomorrow :)

