[Day 186] Prefect cloud, model serving with FastAPI, and SHAP values
Hello :)
Today is Day 186!
A quick summary of today:- using FastAPI for model serving, and running it in Docker
- starting to think about model monitoring
All code, pictures are on my github repo.
Firstly, yesterday I was having version issues between prefect and prefect-gcp - fixed that with the help of Prefect's community slack, and now I can run one file which runs both flows - upload_to_gcs flow and train_model flow. I also realised that for solo (and mini project) devs Prefect cloud is free, so I uploaded my flows to there just to be a bit safer - not having everything locally only.

Next, serving the model for inference
I decided to use FastAPI as it seems very easy to create and run a server. Also when I run a fastapi server, there is a nice /docs page where I can quickly and easily test my endpoints.

The Dockerfile:
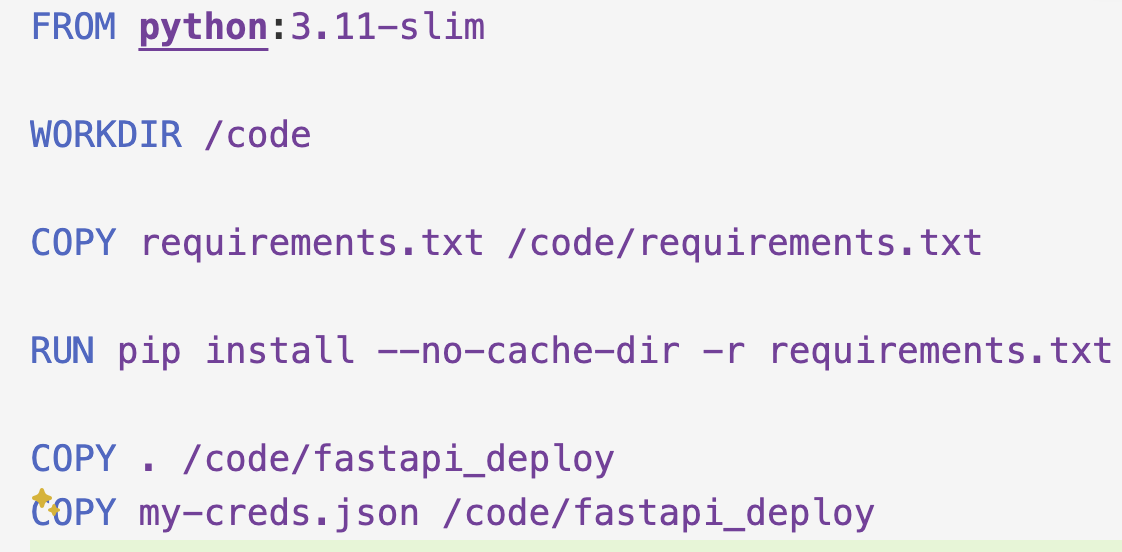
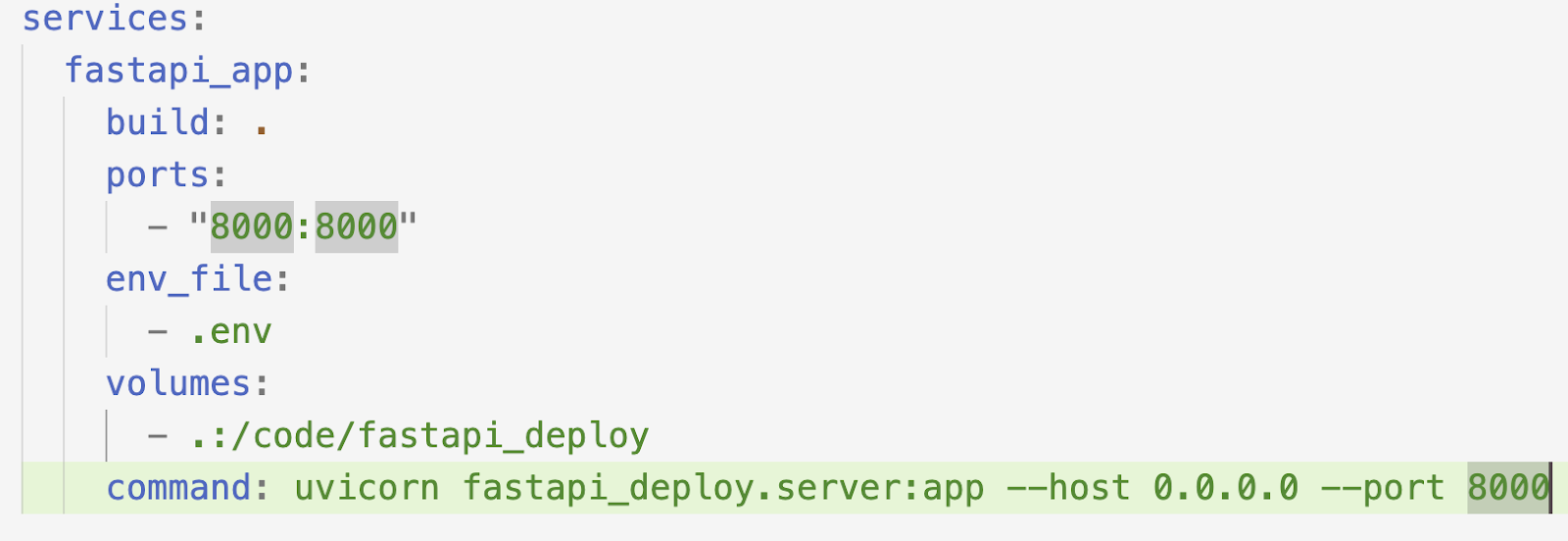
My makefile has the following options (for now at least):

Now that I had model serving (with FastAPI) set up, I started to think about monitoring.
But what can I monitor? The dataset is not only small, but no new data will come in. I can of course set aside some rows of data, or even generate fake data maybe.
I can monitor:
- performance metrics (recall, accuracy, roc-auc, false positive rate, false negative rate, etc)
- fraud/not fraud distribution
- look for anomalies
- optimal threshold
- feature importance
One interesting and new (for me) way to look at feature importance is to look at SHAP values. SHAP shows feature importance based on the contribution of each feature to the model's predictions, averaged over all possible feature combinations, ensuring a fair and consistent representation of their impact.
After some issues with generating visualisations, I got some charts
Fraud SHAP values:


There are some other png files that I managed to create (following this video). All are on my repo.
On another note ~ I realised I might have made a mistake when preparing the dataset I used for the model. What I did was, I had all these variables: NumberOfSuppliments,AgeOfVehicle,AgeOfPolicyHolder,Month,Deductible,MonthClaimed,Make,AddressChange_Claim,PastNumberOfClaims,VehiclePrice,VehicleCategory,Fault,FraudFound_P
And I just got dummies for all. However, I did this without thinking whether ordinal encoding might be better. After some review, doing dummies for all seems fine, but for other cases I need to keep this in mind. Maybe it is something to explore - doing ordinal encoding for some of the vars for which it might be interesting to see the effect on model performance (like vehicle price maybe). Nevertheless, for now doing OHE(dummies) for all seems fine, and the model performance is satisfactory for now.
That is all for today!
See you tomorrow :)
