[Day 176] Testing, Documentation, Deployment with dbt and visualisations with Looker
Hello :)
Today is Day 176!
A quick summary of today:- finished Module 4: analysis engineering and using dbt from the data engineering zoomcamp
A preview of what I created in the end

Continuing from yesterday with dbt ~
First I learned about testing and documenting dbt models
We need to make sure the data we deliver to the end user is correct, and how do we make sure that we are not building our dbt models on top of incorrect data?
dbt tests
- assumptions that we make about our data
- tests in dbt are essentially a select sql query
- these assumptions get compliled to sql that returns the amount of failing records
- tests are defined on a column in the .yml file
- dbt provides basic tests to check if the column values are:
- unique, not null, accepted values, a foreign key to another table
- we can create custom tests as queries
Before writing tests, to ensure our data's schema is correct we can autogenerate it using a package
First, include the package in packages.yml (and run dbt deps to install it)



These schema.yml files are not needed to run the models, but are recommended because it serves as documentation.

Now, adding tests is fairly straighforward
For example, we can add tests to check that the column tripid is unique and not null

Another test to check that pickup_locationid and dropoff_locationid are within the existing locationids in a reference table


And when we run dbt build now
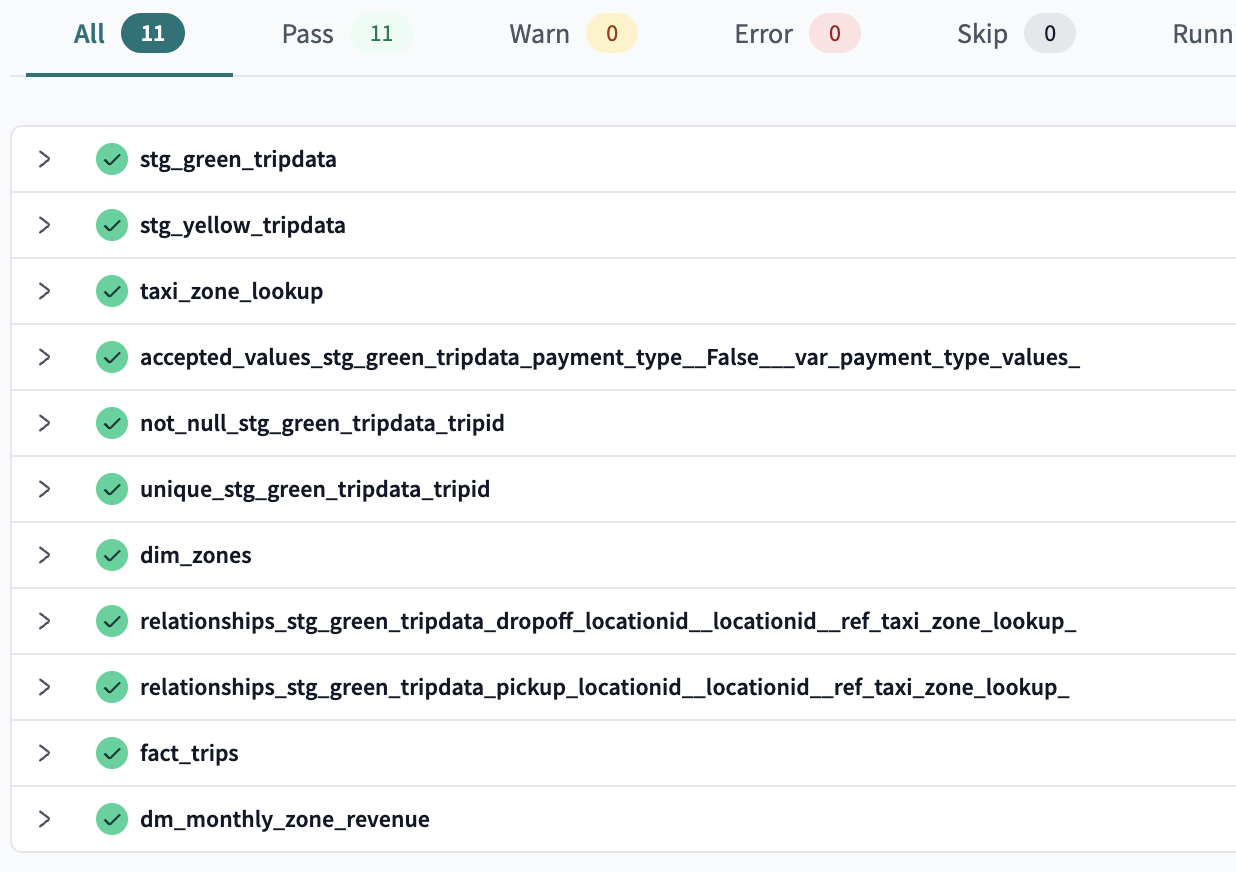
If we check the pics from above, there is a description: "" field, which is part of dbt documentation.
- dbt provides a way to generate documentation for our dbt project and render it as a website
- the documentation includes:
- information about the project
- model code
- model dependencies
- sources
- auto generated DAG from the ref and source macros
- descriptions (from .yml file) and tests
- information abour our data warehouse (information_schema)
- column names and data types
- table stats like size and rows
- dbt docs can also be hosted in dbt cloud
Once we are happy with the descriptions in our schema.yml files
for example:

And we get a docs page



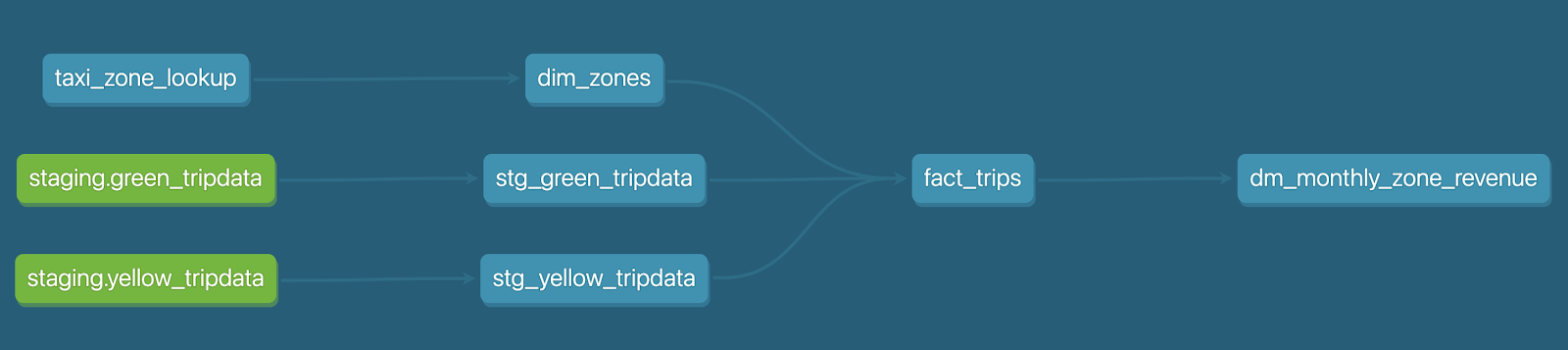
To deploy we need to create a PROD environment


Where we have a Job settings section



I pressed Run now and I see a new run:


Going back to creating jobs ~ we can also create CI jobs
There is a git trigger on pull request


Create a new report, make a connection to BigQuery and we can see the fields of the selected table


That is all for today!
See you tomorrow :)

