[Day 175] Learning about and using dbt cloud
Hello :)
Today is Day 175!
A quick summary of today:- basic SQL in BigQuery
- continued Module 4: analytics engineering and dbt from the data eng camp and learned about dbt
There were some bits from Module 3 that I did not finish. About using BigQuery to create a partitioned and clustered dataset and see the impact it has on processed data.
Using the infamous nyc taxi dataset, I executed some simple queries on creating external datasets in BigQuery and could see the effect of partitioning and clustering
First create a non-partitioned and partitioned table in BigQuery

The dataset is by dates so we are using one of the datetime columns to partition by it. Below we can see a significant drop in processed data when doing a simple WHERE between dates on the non-partitioned vs partitioned tables.
I faced an issue here because when creating the partitioned data, in BigQuery there is a table details section where it says 0 partitions. And I was really confused because the data I was partitioning is 10GB and I saw that for other people it says there are partitions there. But for me it says 0. I kept rerunning and changing/uploading more data.
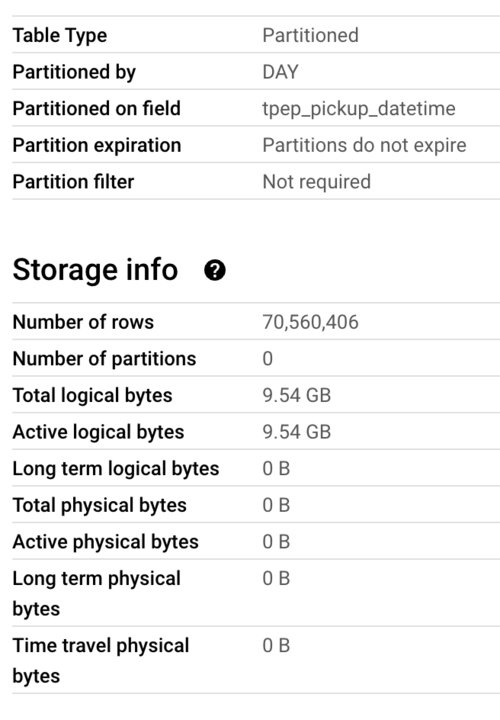
But it turns out that even though it says 0 partitions in the Number of partitions part, my dataset was indeed partitioned and the results were clear (as in the pic)

And finally a table that is both partitoned and clustered, and there is a decreased in processed MB of data in the two same queries as well.

Now onto Module 4
First I learned about ETL vs ELT

- slightly more stable and compliant data analysis
- higher storage and compute costs
- faster and more flexible data analysis
- lower cost and lower maintenance
- deliver data understandable to the business users
- deliver fast query performance
- prioritise user understandability and query performance over non redundant data (3NF)
- Bill Inmon
- Data vault
- measurements, metrics or facts
- corresponds to a business process
- 'verbs'
- corresponds to a business entity
- provides context to a business process
- 'nouns'
- contains raw data
- not meant to be exposed to everyone
- from raw data to data models
- focuses on efficiency
- ensuring standards
- final presentation of the data
- exposure to business stakeholders
What is dbt?

Workflow we will use:
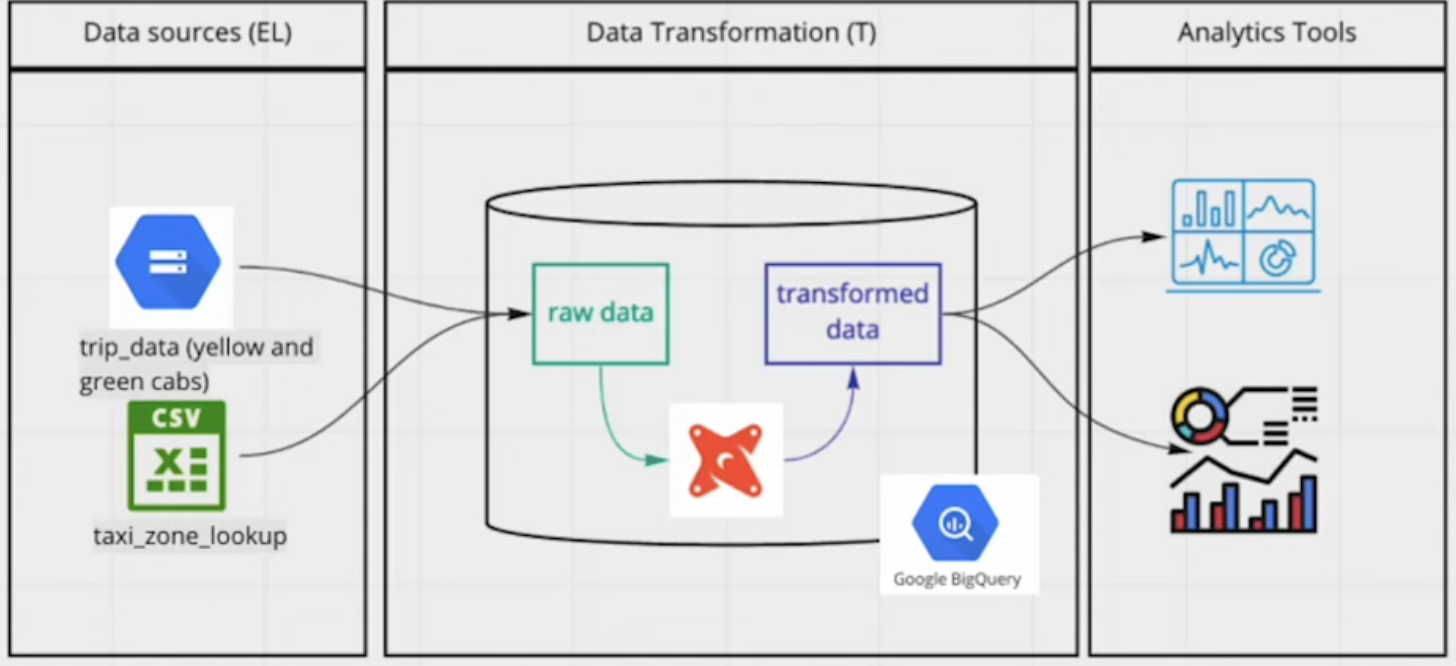
This took some time to figure out creating right folders and access to my repo, but in the end:



- Ephermal - temporary and exist only for a duration of a single dbt run
- View - virtual tables created by dbt that can be queried like regular tables
- Table - physical representations of data that are created and stored in the database
- Incremental - powerful feature of dbt that allow for efficient updates to existing tables, reducing the need for full data refreshes
- the data loaded to our datawarehouse that we use as sources for our models
- configuration defined in the yml files in the models folder
- used with the source macro that will resolve the name to the right schema, plus build the dependencies automatically
- source freshness can be defined and tested
- CSV files stored in our repo under the seed folder
- benefits of version controlling
- equivalent to a copy command
- recommended for data that does not change frequently (and is not huge)
- runs with `dbt seed -s file_name`
- macro to reference the underlying tables and views that were building the data warehouse
- run the same code in any environment, it will resolve the correct schema for us
- dependencies are built automatically



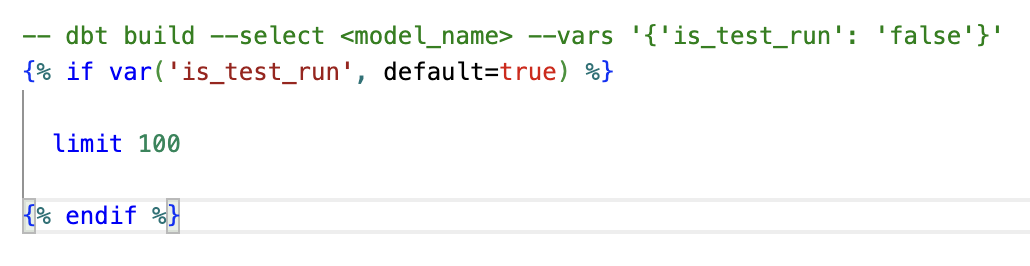
Next, I learned about Macros
- use control structures (i.e. if statements and for loops) in SQL
- use env vars in our dbt project for production deployments
- operate on the results of one query to generate another query
- abstract snippets of SQL into reusable macros - these are analogous to functions in most programming languages


- like libraries in other programming languages
- standalone dbt projects, with models and macros that tackle a specific problem area
- by adding a package to a project, the package's models and macros will become part of that project
- imported in the packages.yml file and imported by running `dbt deps`



- useful for defining values that should be used across the project
- with a macro, dbt allows us to provide data to models for compilation
- to use a variable, we use the {{ var('...') }} function
- variables can be defined in two ways:
- in the dbt_project.yml, or
- in the command line


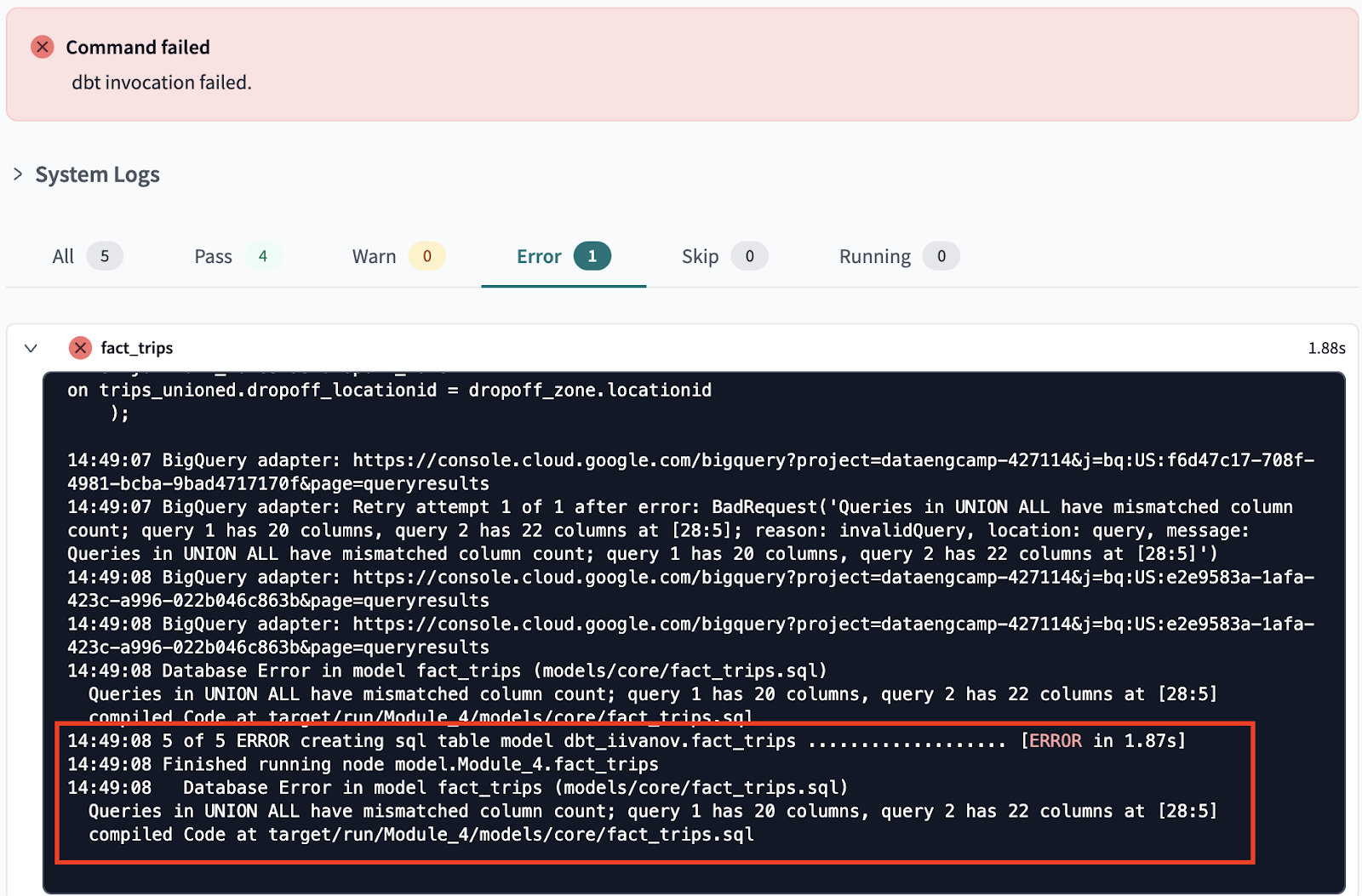


This is not all for Module 4, tomorrow hopefully I will cover the rest ^^
That is all for today!
See you tomorrow :)

