[Day 173] Terraform, GCP, virtual machines, data pipelines
Hello :)
Today is Day 173!
A quick summary of today:- learned more about terraform and how to set up a GCP VM and connect to it locally
- used mage for some data engineering pipelines with GCP
Last videos from Module 1: terraform variables, GCP set up
Turns out there is a bit more of terraform from the data eng zoomcamp, and today I covered it.
After learning how to connect to gcp using terraform and create a storage bucket, the first thing today was creating a bigquery dataset



Create a variables.tf file and put a variable like:


The next part was an instruction on setting up GCP (cloud VM + SSH access)
First was creating an ssh key locally





`export PATH="${HOME}/bin:${PATH}"`
And now we have it

Then installed pgcli with conda





Next, I installed terraform for linux
And if I want to stop and restart the instance I can do it through the terminal (`sudo shutdown now`) or the GCP console. And when I start it again in order for the quick ssh connection command to work, I need to edit the config file's HostName that I created earlier.
I found that if I restart the VM and want to use terraform, I need to set my credentials and gcloud auth using (and also just saving the commands for later):
Next onto Module 2: workflow orchestration
My good old friend mage.ai. Let's hope for at least less errors than when I covered it in the MLOps zoomcamp.
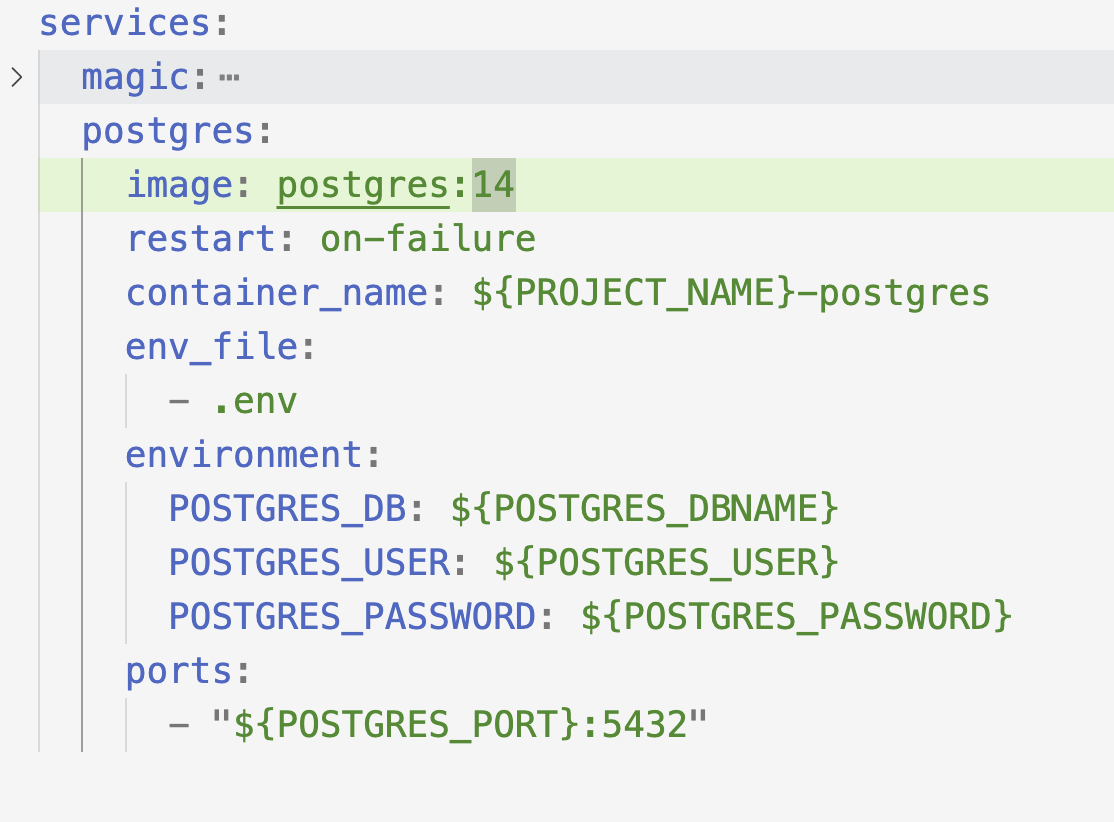
The first bit was to establish a connection with the postgres database which is ran alongside mage in docker-compose.yml

Next is writing a simple ETL pipeline - loading data from an API to postgres, where I just load taxi data in the first block using data type checking, do a little bit of preprocessing in the 2nd block and then make a connection to my db and load the data there in the 3rd block

Loading data to google cloud storage is very easy - just adding a google cloud storage (GCS) data exporter block, and putting my info down and its done


I learned how to use pyarrow (as it abstracts chunking logic) for that as in the below block:



My experience using mage in this course compared to the MLOps zoomcamp is completely different haha. Now, the teacher Matt Palmer did a great job ^^
That is all for today!
See you tomorrow :)
