[Day 159] Learning and using prefect for MLOps orchestration
Hello :)
Today is Day 159!
A quick summary of today:- did Module 3 of the MLOps zoom camp from the 2023 cohort that uses Prefect
Before everything else, I finally got the notebook expert title on Kaggle! :party:

Github repo from today's study is here.
A common MLOps workflow

However, we might have failure points at any of the arrows (connections) between steps.
Prefect comes in when we give an engineer the following tasks:
- could you just set up this pipeline to train this model?
- could you set up logging?
- could you do it every day?
- could you make it retry if it fails?
- could you send me a message when it succeeds?
- could you visualise the dependencies?
- could you add caching?
- could you add collaborators to run ad hoc - who don't code?
The first few could be done quite easily, but the mid/later ones become hard without some kind of extra help like Prefect.
Some terminology:


After some setup ~ and prefect server start ~
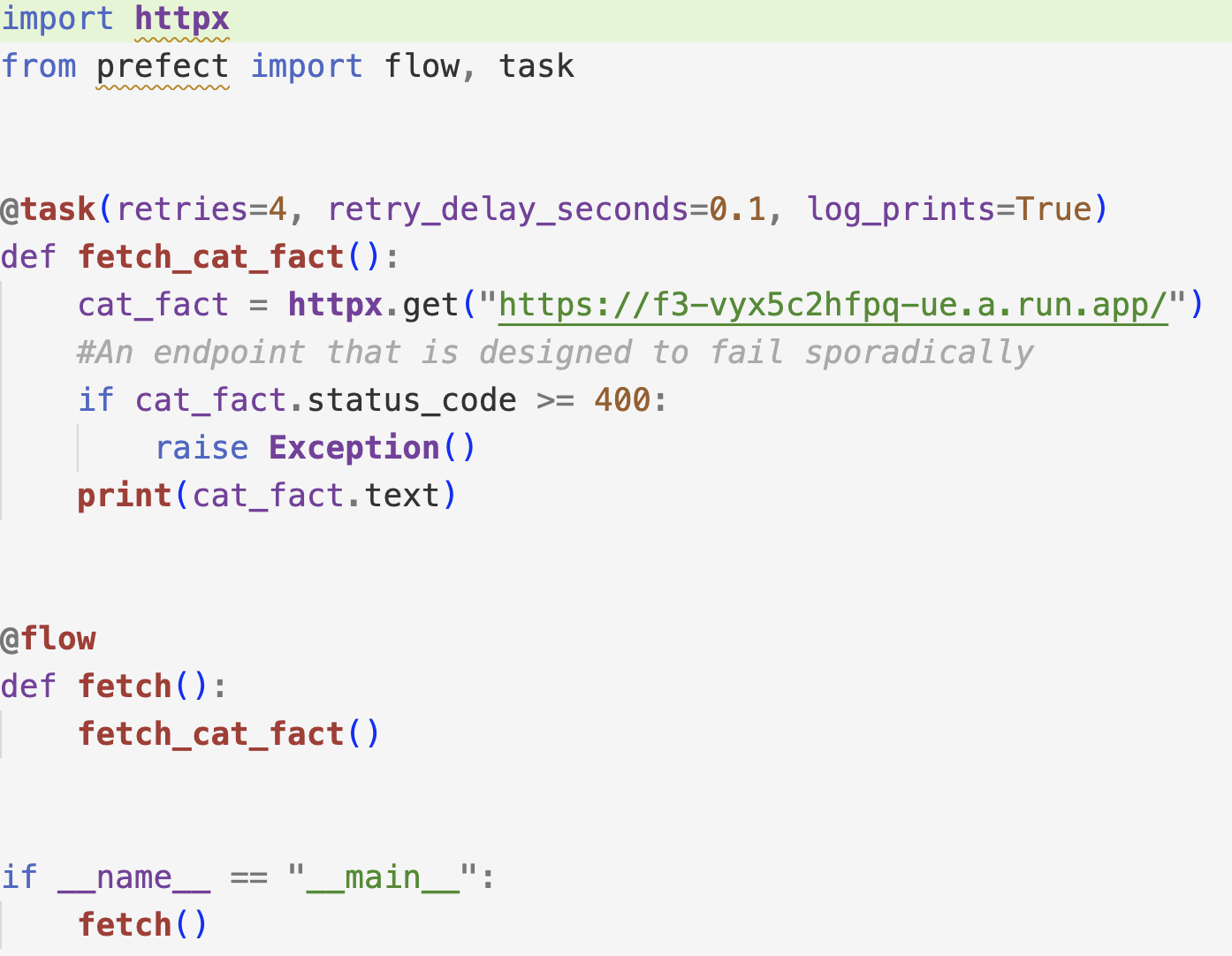


Next, I executed a flow that utilises subflows.
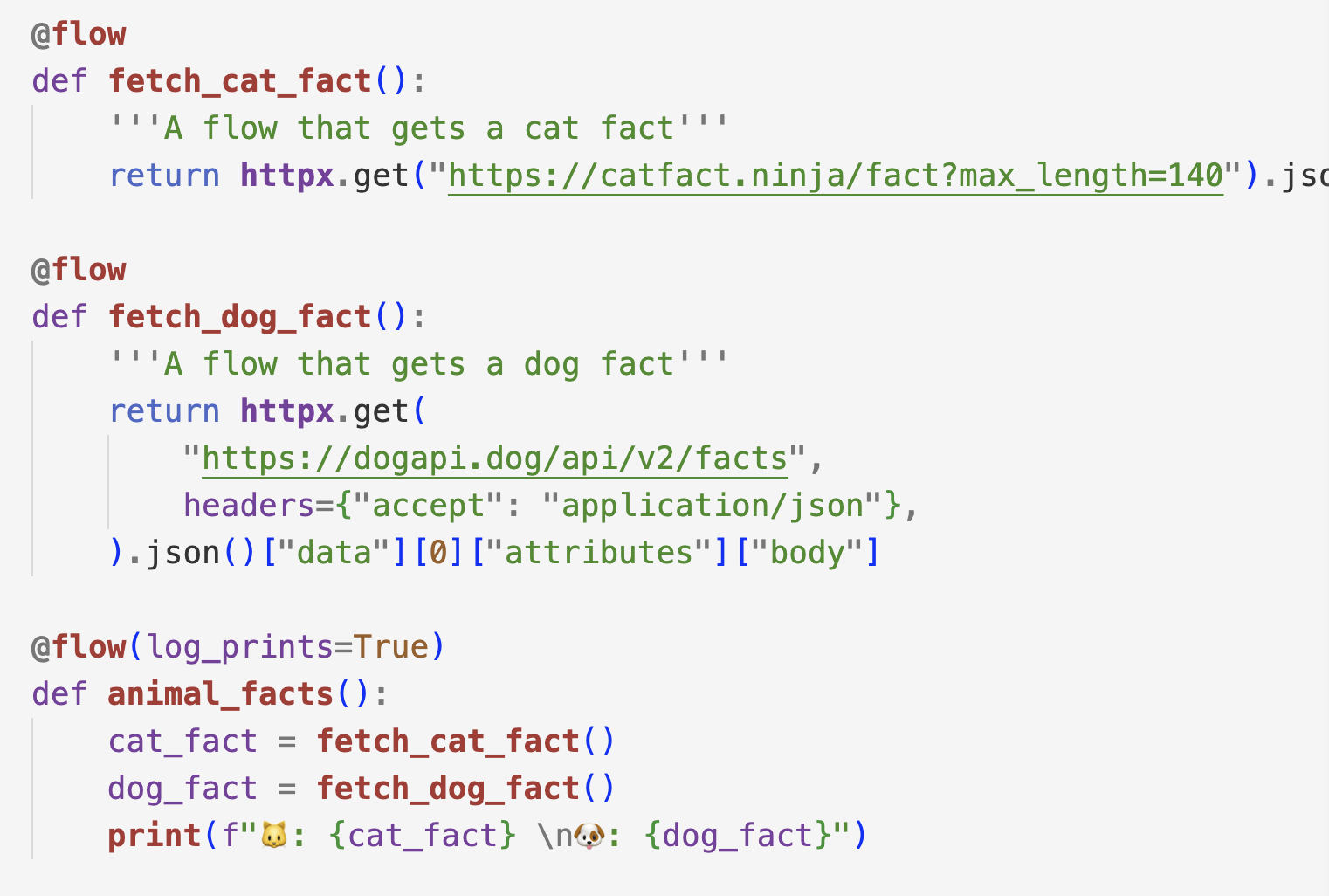

From Module 1, I created a jupyter notebook for taxi prediction, but here, to make it a bit more 'production-ready', the code is a bit more structured as follows:
Create task - read data

Create task - add features


And then, the main flow that executes all the tasks:



(I am writing today's post as I study ~)
Thankfully, youtube came to the rescue!
The commands are a bit different, but I got a deployment working.



In the next bit, I setup AWS - and S3 storage with taxi data and a user with S3 permissions in IAM.
Executed code:
 And the result on the prefect server:
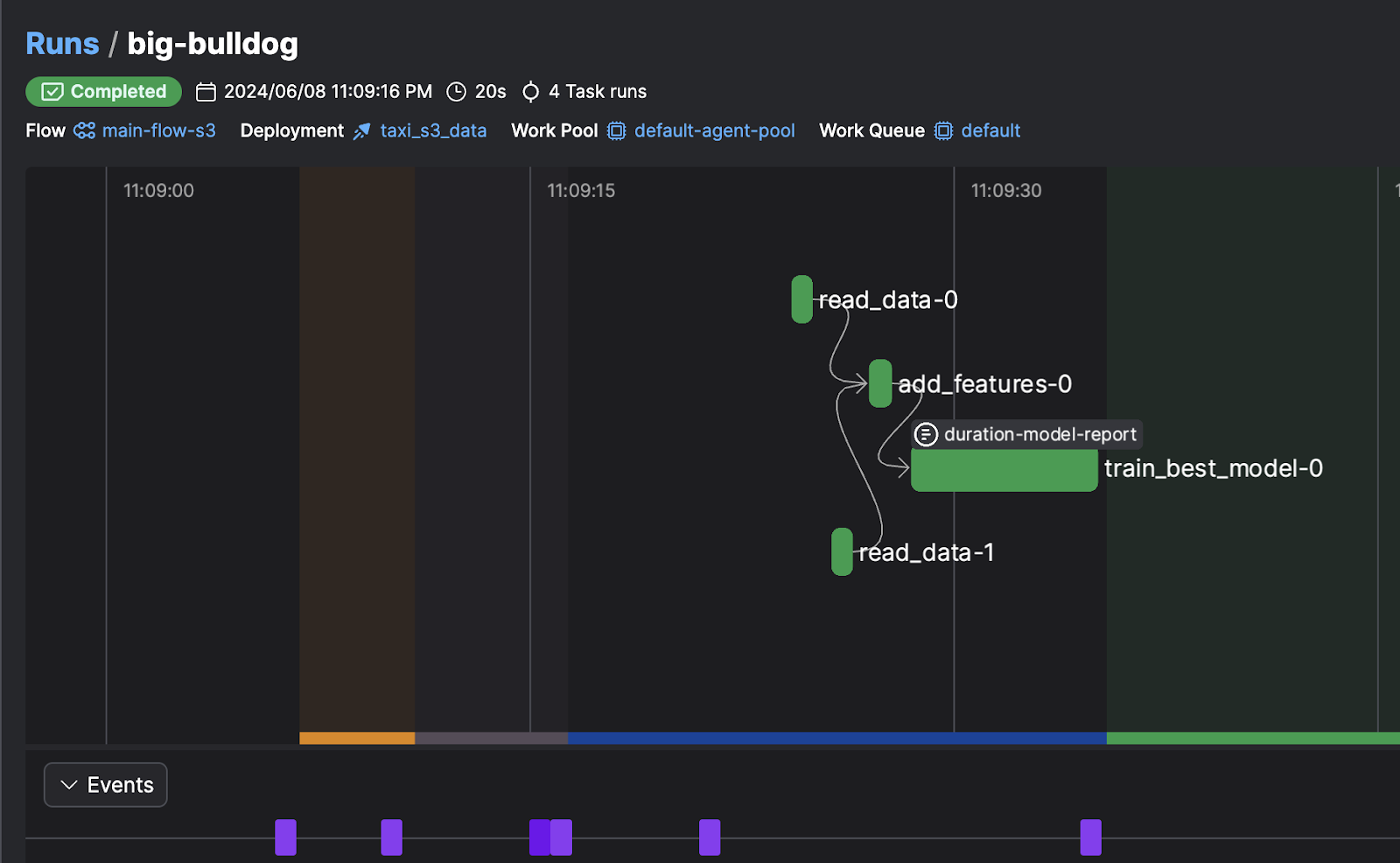
And the result on the prefect server:
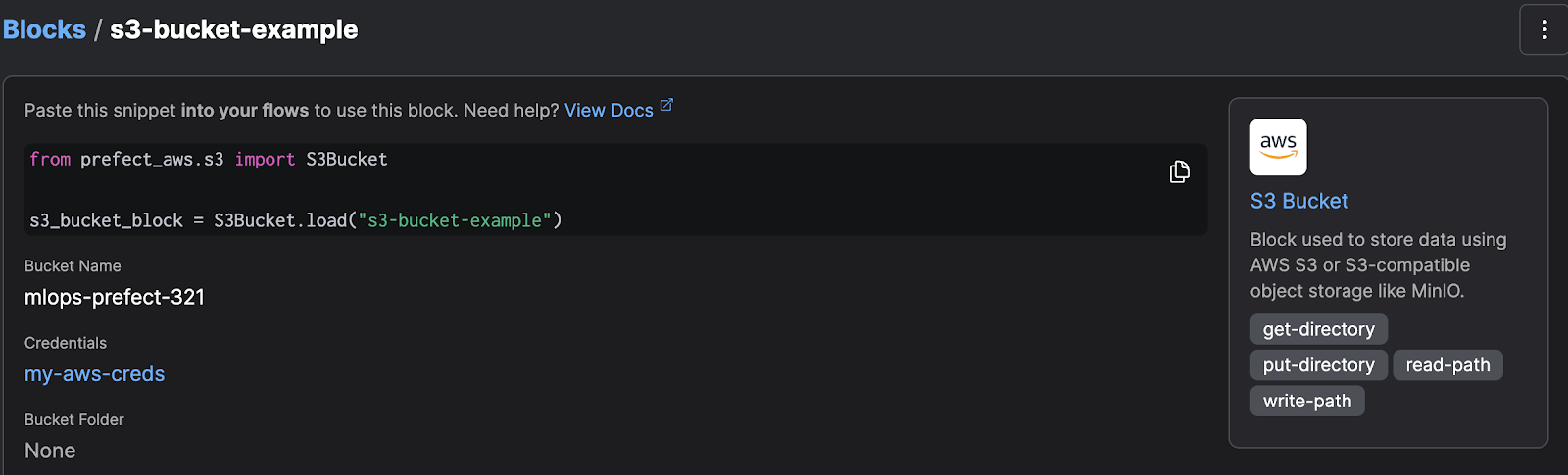
We can use the uploaded S3 data using aws_prefect





The cloud webapp has pretty much the same UI as the local one, and once I logged in, and deployed a flow, I could see:


In the cloud, there are also automations with different trigger options




That is the end of this Module 3 ~
At least for now. I like prefect a lot, and might end up using it for the final project of the MLOps zoomcamp, but will see. I will give mage.ai another go.
That is all for today!
See you tomorrow :)

