[Day 157] GNN design choices and starting an MLOps book on manning.com
Hello :)
Today is Day 157!
A quick summary of today:- read about design choices for GNNs
- started reading a book about MLOps on manning.com
- registered for Korea summer workshop on causal inference
Design choices for Graph Neural Networks [arxiv]
I saw this paper from the last short lecture from XCS224W: ML with graphs, it looks into how different design choices affect a GNN model's performance. It caugt my eye as some of the findings as to what is useful could be tested/applied in my work/research at the lab.
Below are some of the interesting findings:

Design a Machine Learning System (From Scratch) [book]
The book will teach me how to:
- Build an ML Platform
- Build and Deploy ML Pipelines
- Extend the ML Platform using various tools depending on use cases
- Implement different kinds of ML services using the ML life cycle as a mental model
- Deploy ML services that are reliable and scalable
A quick summary of chapter 1: Getting Started with MLOps and ML Engineering
An ML project begins with the experimental phase. This phase involves continuous iterations and adjustments across various steps, such as model training and evaluation, to refine models based on complex data and performance metrics. Building an orchestrated pipeline automates these steps, reducing errors and streamlining the process before full automation in later stages.

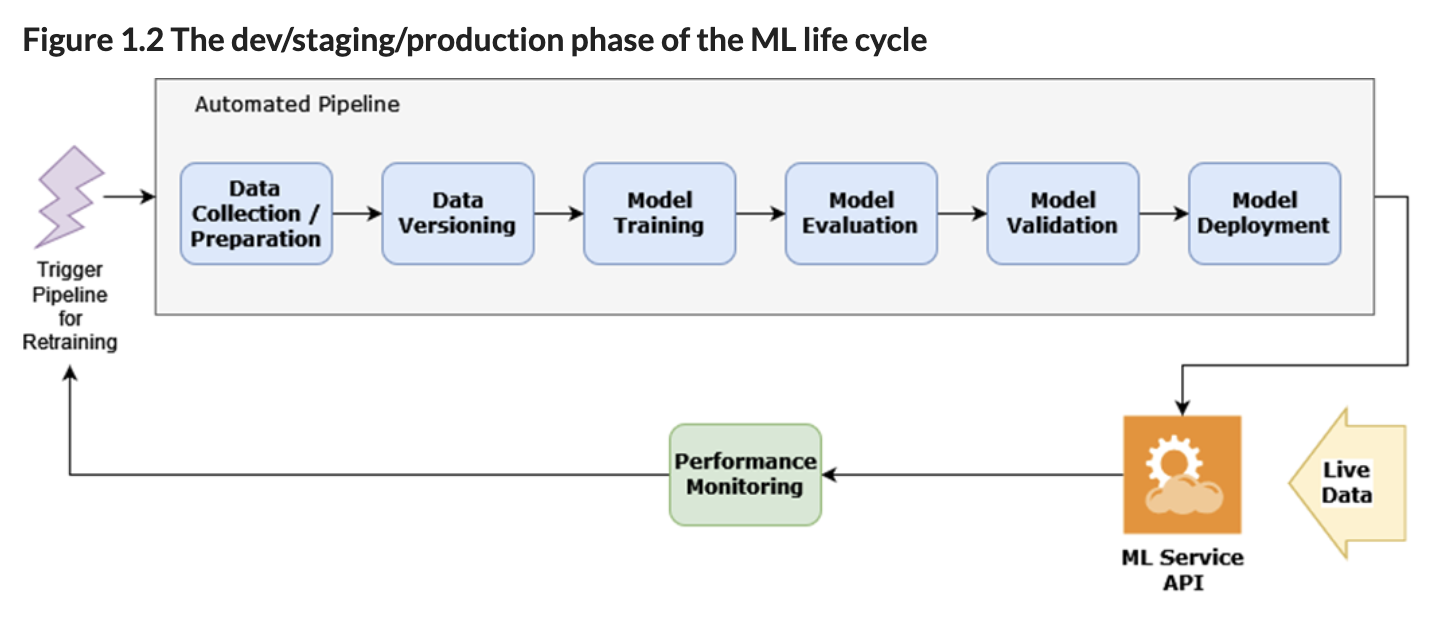
An ML platform enables practitioners to develop and deploy ML services by integrating various tools essential for the ML life cycle. Typically, it comprises a collection of loosely related software that evolves as team maturity and use case complexity increase. This book guides you through building an ML platform using Kubeflow, covering components like pipeline orchestration, feature stores, and model registries.

A short summary Chapter 2: What is MLOps?
First step - data collection- Data relevance to problem domain
- Size of the dataset with respect to problem complexity
- Quality of the dataset. Prevention of harmful biases and unintentional leakage of samples
- Distribution of data and features is representative of the deployment environment.
- Sufficient diversity in the data collection process that defines the problem domain well.
- Lineage and detailed tracking of raw data, intermediate versions and annotated datasets
Second step - EDA
- What does my data look like? What is its schema? Can the schema change? How would I guard against invalid values? Does the data require cleaning?
- How is my data distributed? Are all targets equally represented or should there be additional class balancing?
- Does my data have robust features for the task I have in mind? Are the features expensive to compute?
- Does the input data vary cyclically? Does it exhibit correlations to external factors that are not modeled ?
- Are there any outliers in the dataset? What must be done to outlier values in production ?
Third step - modelling and training
- Model and data versioning
- Experiment tracking
- Model training pipelines
- Hyperparameter search
Fourth step - model evaluation
- choosing the appropriate metrics
- examine and analyse misclassified samples, error patterns
Fifth step - deployment
- to a specific environment, or API endpoint
- staging vs production
- track anomalies in data and model performance
- data/performance/error monitoring
- need reliable notification/alert system
- implement bug fixes to fix issues and shortcomings in the model in production.
- collect data to train the model on specific edge cases and improve performance
- mitigate for data drift by informing the data collection component and retrain a new model
Korea summer workshop on causal inference 2024
Here is the post (in Korean)
It spans over 4 days - June 13, 20, 27, 28 and some of the covered topics are:
- causal inference in policy making and various practical applications
- best practices for online controlled experiments and experiments platform
- data-driven decision-making
- data science & casual ML/AI in the generative AI era
That is all for today!
See you tomorrow :)

