[Day 135] Going deeper into MLOps
Hello :)
Today is Day 135!
A quick summary of today:- covered module 2 of the mlops-zoomcamp by DataTalks club about experiment tracking and model management
- cut 2 more videos for the Scottish dataset project
Firstly, about using mlflow for MLOps
Maybe this is because I am starting to learn about MLOps for the 1st time and I don't know other tools, but WOW mlflow is amazing. Below are my notes from the module 2 lectures. Full code on my github repo.
First, some important concepts
- ML experiment: the process of building an ML model
- experiment run: each trial in an ML experiment
- run artifact: any file that is associated with an ML run
- experiment metadata
- the process of keeping track of all the relevant info from an ML experiment (could include source code, environment, data, model, hyperparams, metrics, other - these can vary)
- reproducability
- organization
- optimization
- error prone
- no standard format
- visibility and collaboration


We can spin up mlflow with: mlflow ui --backend-store-uri sqlite:///mlflow.db


In the UI, we see
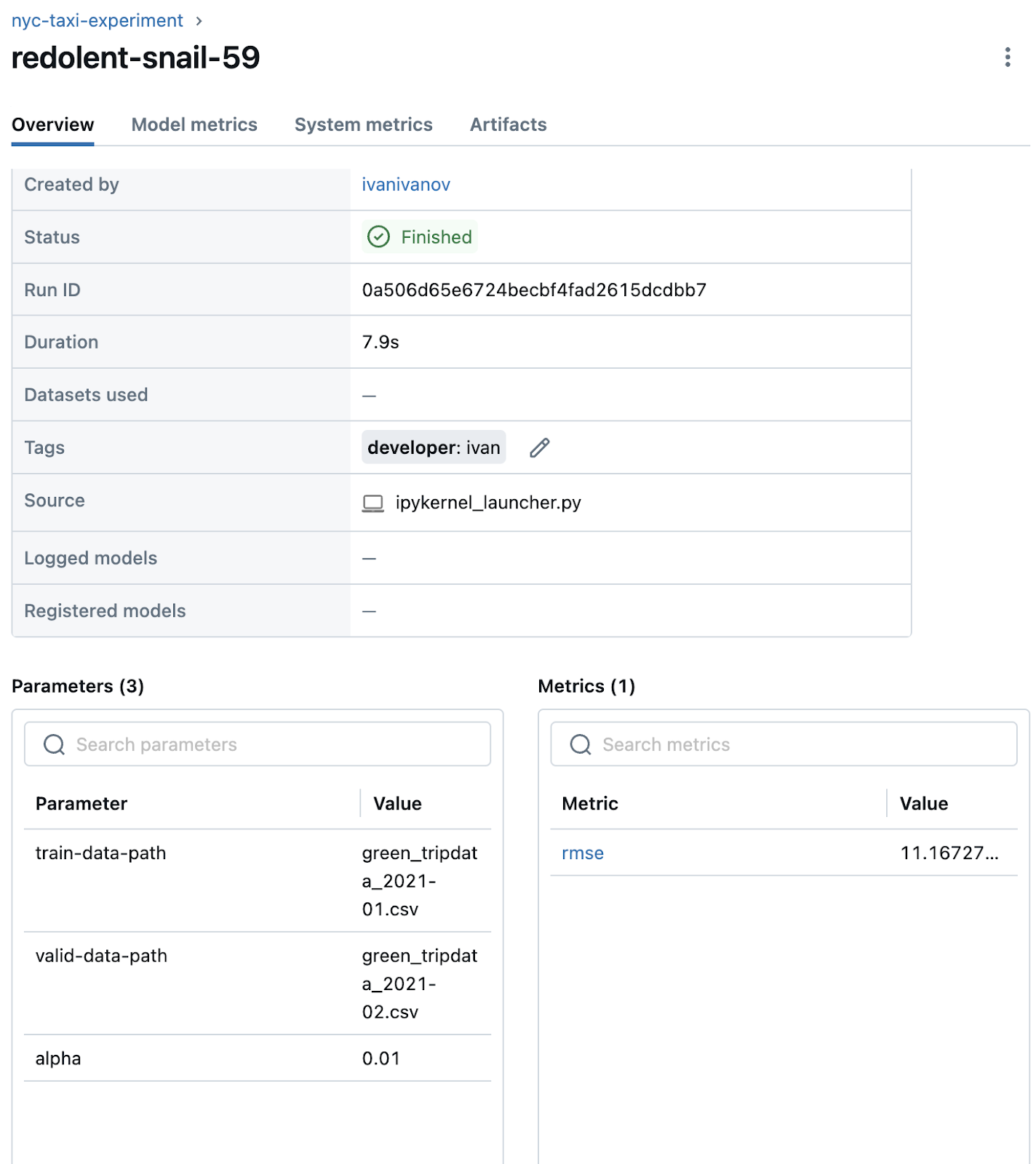

Run another model with alpha=0.1, and we can compare the two

Next, doing hyperparam optimization using xgboost and pyperopt






How do we go about model selection?
A naive way would be to choose the model with lowest rmse


Instead of writing lines of what to log, we can use autolog, and when we run the model with the best params from the hyperparam search







Next, I learned about model management

- error prone
- no versioning
- no model lineage

Instead of just getting the bin file, we can get better logging using


Using the saved model for predictions mlflow provides this sample code when a model is logged in the artifact tab



Next, model registry
Imagine a scenario where a DS sends you a developed model and asks for me to deploy it. My task is to take it and run it in prod. But before I do it, I should ask what is different, and what is the purpose. What are the needed dependencies and their versions which are needed for the model’s environment

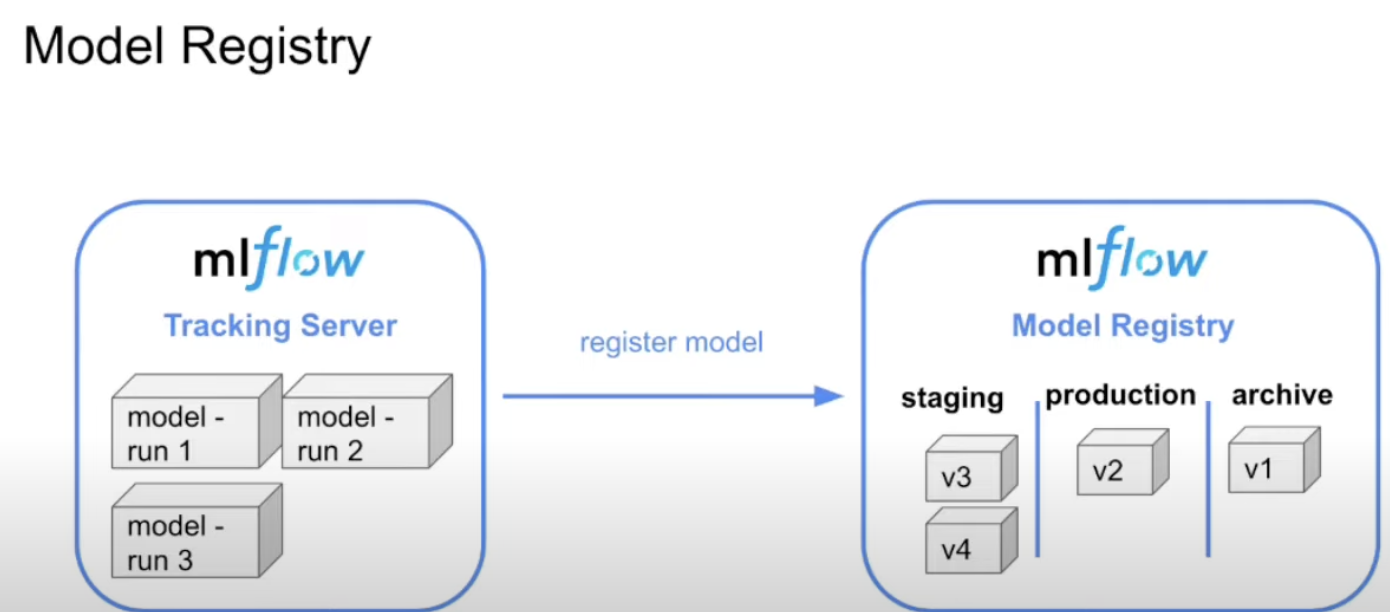



Next, I learned about mlflow in practice

1 - no need to use mlflow, saving locally is fine
2 - running mlflow locally would be enough. Using model registry would be a good idea to manage the lifecycle of the models. But it is not clear if we can just run it locally or need a host.
3 - MLflow needed. We need a remote tracking server. Also model registry is important because there might be different ppl with different tasks.




This website shows comparison between mlflow and paid/free alternatives.
Secondly, about the Scottish dataset
Today I finished the last 2 videos from my collaborator

I also added some other metadata for each clip


Tomorrow and Friday is AWS Summit Seoul 2024, and there are a lot of panels each day (2 days in total). So I will share my experience and attended panels.
That is all for today!
See you tomorrow :)

