[Day 127] Serving an API endpoint for news classification + Stanford's CS109
Hello :)
Today is Day 127!
A quick summary of today:- learned a bit more about Docker's potential and deployed a model to classify news text into categories (github)
- started watching Stanford's CS109 Probability for computer scientists and the professor is so amazing
- saw a visualization of how activations change over epochs
Firstly, about the mini-project
After yesterday, I wanted to learn more about what Docker can do when it comes to MLops. Luckily, I found this tutorial which develops a text's language classification model, bundles it with Docker and publishes an endpoint to Heroku. How did I do it?
For a start, I wanted to do a simple model too, so I chose to write a simple model that classifies a piece of news into categories like sport, politics, tech, etc. I found a dataset on Kaggle and trained a simple multinomial naive Bayes that takes a tokenized bag of words and classifies them into sports, tech, politics, entertainment and business (the code is in my repo).
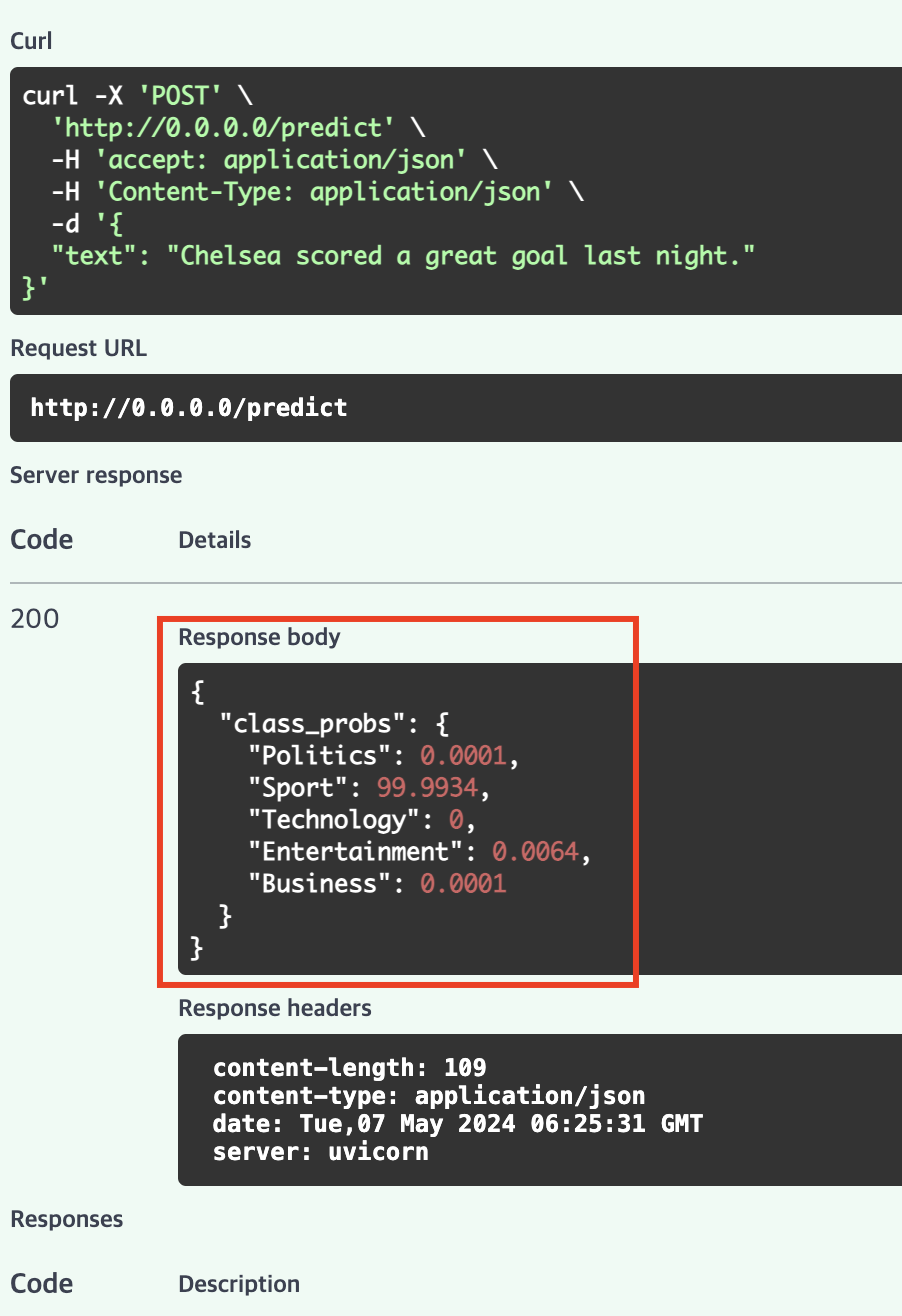
Then I packaged the model with pickle, and using FastAPI, I created an endpoint that takes text, sends it to the model and we get a response back like:
Query: 'Chelsea scored a great goal last night'
Response: {'Politics': 0.0001, 'Sport': 99.9926, 'Technology': 0.0, 'Entertainment': 0.0073, 'Business': 0.0}
Using FastAPI, using the API locally was easy, I went to the chosen port

But instead of installing Postman to send requests to the API, FastAPI provides a /docs endpoint where we can test the functionality (we can see all the available endpoints)


Secondly, about Stanford's CS109 Probability for Computer Scientists course
I randomly stumbled upon it, and wow... Professor Chris Piech is so amazing. His teaching is so engaging and even though I am just sitting in front of a screen, his excitement to teach is making me even more excited to learn.
Today I watched Lecture 14: Modelling
It was mainly about joint probability distributions, constructing Bayesian networks and using marginalization to obtain the probability distribution of a subset of a set of random variables from the joint probability distribution of all variables.
Lecture 15: General Inference
It introduced covariance/correlation, rejection sampling, using continuous and binary variables in Bayesian nets and sampling,
Lecture 16: Beta distribution
It talked about the Beta distribution - used as a prior distribution for modeling probabilities

In cases like the below, we can say the in the 1st case, the beta distribution is like uniform, but the 2nd we can that the statement is more reliable thanks to the beta distribution.

Finally, about the visualization of activation functions in a neural net
In the video linked, we are shown non-linear data (on the left), and the neural net that will fit it (on the right)
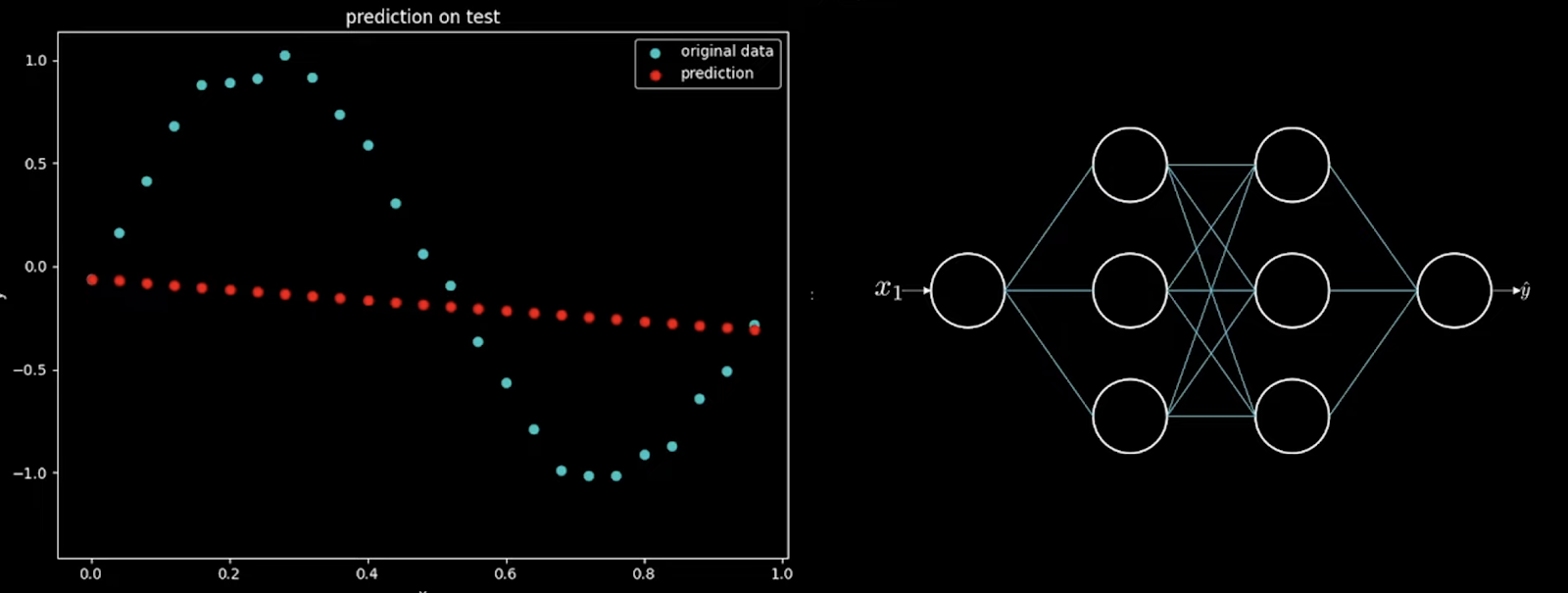
During training, we see how each neuron contributes to the change from a straight line to fitting this curvature.
At the start:




The video has animations as well and it is a very neat way of showing how each neuron controbutes.
That is all for today!
See you tomorrow :)

