[Day 115] Exploring HuggingFace's capabilities and submitting 3rd homework from the ML with Graphs course
Hello :)
Today is Day 115!
A quick summary of today:- submitted 3rd homework of XCS224W:ML with Graphs
- explored different huggingface capabilities with DeepLearning.AI
As for the homework, we are not allowed to share anything from it. But I can happily share

As for the huggingface tutorial
It showcased the different type of models that were available. Below is a summary.
Building a chat pipeline


Text translation


Zero-shot audio classifier



Object detection
(code before the pic: od_pipe = pipeline("object-detection", "./models/facebook/detr-resnet-50"))


We can use gradio as a sample interface

I passed a picture of mine to check haha



Example image


Using the dog and woman pic again for multimodal QA

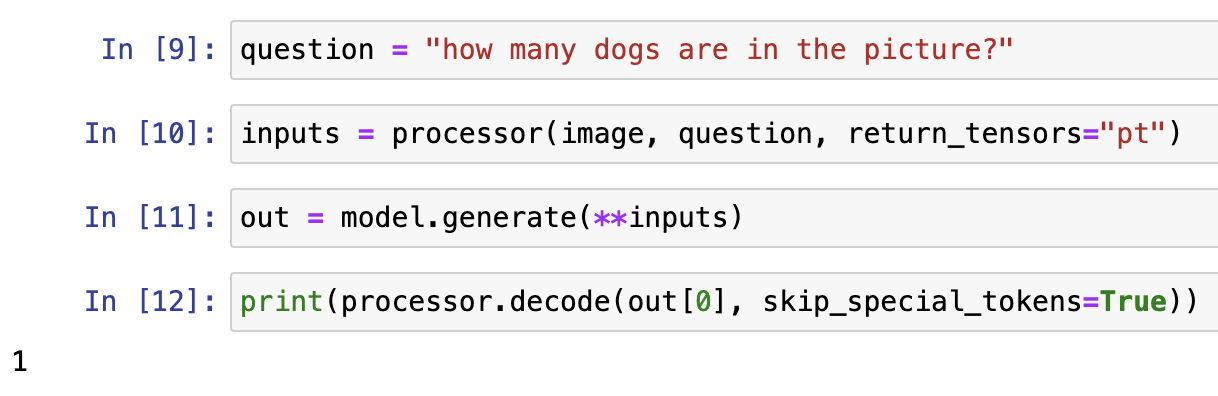


Giving labels: a photo of a cat, and a photo of a dog, we can get the models' probs for each label.


On hugging face to deploy a model, we need to:
1. Create space

2. Create requirements.txt and app.py files
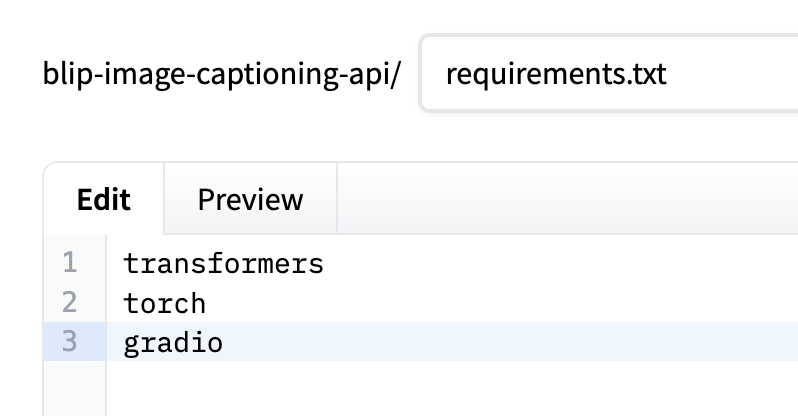

In huggingface, the interface shows



The link is here, but I believe it has a limited runtime.
It was a useful tutorial showcasing the code needed to run various open source models and perform various tasks.
That is all for today!
See you tomorrow :)

