[Day 81] RAG from scratch - chunking is very important!
Hello :)
Today is Day 81!
A quick summary of today:- Continued with my custom RAG from scratch project - extracting knowledge from a bank's terms and conditions (github repo)


Now... given an allegedly more simple pdf, I used the code as it was to get outputs. But the results were just... really bad. Most times even though the scores were high, and the top-1 included the exact answer, the output was ~'the context does not include {query} information'.
I decided to go back to the start, where I preprocess the pdf, and explore more chunking mechanisms. I found this youtube video exploring different chunking methods.
It covered:
- Character split (which I was using)
- Recursive character split
- Document spcific splitting
- Semantic splitting
- Agentic splitting
This is the final text_splitter I went with:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=0) (tbh, I am writing this blog now and 1500 might be an overkill)
I played around a lot with chunk_size and chunk_overlap - to see the effects, and I don't think I mastered knowing the impact yet. I am sure 1500 chunk_size is even that good. Frankly, in the preprocessing there are other components like splitting, regex-ing characters - maybe there are better ways to do these. It will take trial and error to figure this.
The query list I used to see results is:

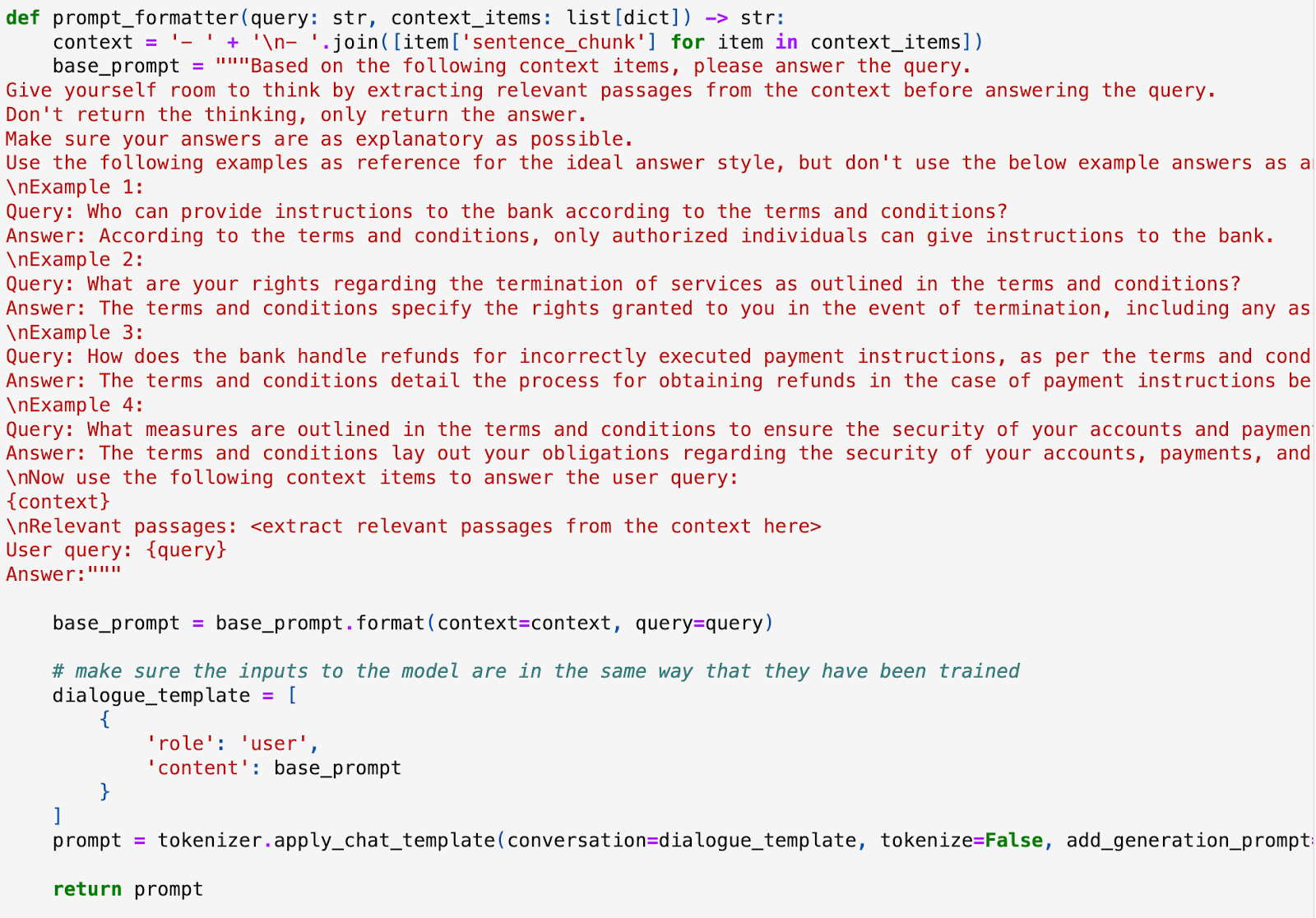
After settling on chunk_size 1500 and chunk_overlap 0, I decided to streamline the process a bit, so I created executable preprocess_pdf.py and rag.py files - can be seen in the repo.
As for results, they are incosistent...
Example is this 'What is meant by Business Day?' query.
The top-1 context includes the answer, but some times I get the answer, sometimes I do not.
That is all for today!
See you tomorrow :)

