Hello :)
Today is Day 73!
A quick summary of today:- Covered lecture 6: Generation algorithms and 9: Experimental design and human annotation from the CMU 11-711 Advanced NLP course, from which I found out about:
- Why pre layer normalization is better than post layer normalization in transformers
1) Minimum Bayes Risk decoding for modern generation techniques (Bertsch and Xie et al., 2023)
When we get to the generation step of a language model, predicting and outputting the next token in a sequence, we can use methods such as greedy decoding or beam search to select tokens that have a high probability. But MBR which was originally proposed by Bickel and Doksum in 1977, questions whether we actually want to get the highest probability token.
Outputs with low probability tend to be worse than the opposite. But if we just compare the top outputs, it is less clear, as the outputs with the top probabilities might look similar (for example, both The car ran away and The cat sprinted off mean the same thing, and if one has higher prob than the other, which one do we actually want?)
However, in such a case the top output's meaning is actually different from the next 3 ones. The probability is split amongst the 2 meanings - a cat sitting down and a cat running away, so we want the first or the second meaning? So, just going by probability might not be a good idea. The cat sat down has the highest probability, but its meaning is different compared to the other top answers. So, if 1 particular meaning has multiple top outputs (like the meaning of a cat running away), then choosing one of those would be lower risk than picking the top probability (given that the probabilites are similar to each other). So this begs the question - actualy, do we want an output with high probability and also relatively low risk?
Using a G evaluation function to measure risk (like BLEU) we can measure and choose something that is low risk (this particular output is similar to a lot of other outputs in this set), then we sum up to choose an output that has high probability.
2) Constrained decoding: FUDGE (future discriminator for generation) (Yang and Klein, 2021)
The idea is we want a sequent output that satisfies a constraint of being formal. At each predict step we get the outputs of what the model predicts is the next token (blue), but also a 2nd distribution (red) which tells us, given the context, how likely is that the sentence will be formal at the end. We multiply the 2 distributions, and then sample from this final (purple) distribution which contains info about how likely are output tokens but also the likelihood of satisfying a particular constraint. How do we know what is format at the end of the generation (how do we estimate the red)? We train a model(discriminator) on prefixes to guess whether the generated sequence would be formal.
3) Pre vs Post layer normalization in Transformers
I learned about the usage of layer normalization in transformers and that there is pre vs post layer norm, but I did not know the exact reason why. Today, I found this nice article that clears things up.
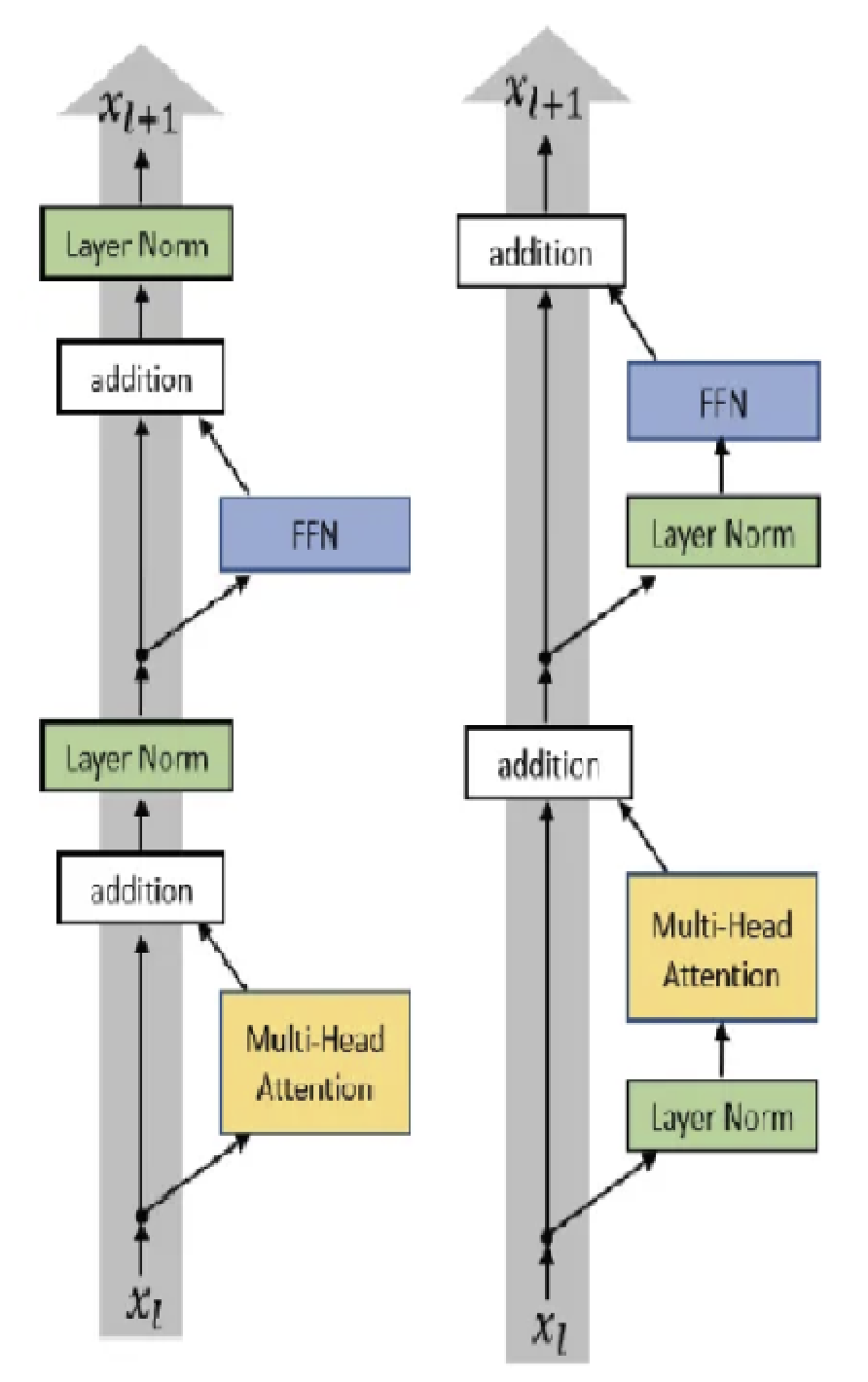
The original transformer had post-LN which places the layer norm between the resid block, but in pre-LN, it is put inside the resid block.
Left is post-LN, right is pre-LN
The post-LN architecture had to use a learning rate warm-up stage, after which a normal scheduler is used. But this warm-up stage could slow down optimization and it was another hyperparameter for developers to worry about.
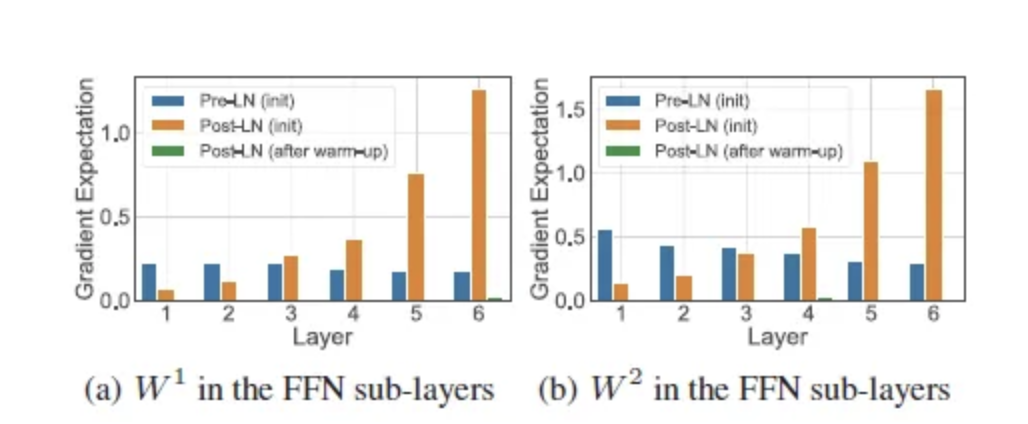
The gradient of the parameters for post-LN satisfy:
and for pre-LN:
for pre-LN the scale of the gradients is controlled by the layers (L) so it is much smaller. If the gradients get too high, this can affect training and can lead to exploding gradients.
As we can see from the graph, with post-LN the gradients keep increasing with layer depth, but when we have the division by L in the formula above, the layer normalization keeps gradients steady (normalizes them).
That is all for today!
See you tomorrow :)