Hello :)
Today is Day 72!
I am amazed. It is still ongoing and they upload the lecture videos and all the information is on the course website. I had a look at the syllabus and saw that the first few lectures are:
Given I have covered CS224N by Stanford, I felt confident and skimmed over the lectures just to check for any new info, and then decided to jump into assignment 1. WOW!
Assignment 1 felt great, it was challenging, difficult and made me read through research papers like (RMS layer norm, and Adam) to implement a Llama model from scratch!
I uploaded all my assignment code to
this github repo, but the main files that needed to be implemented are classifier.py, optimizer.py, rope.py, and llama.py. Below I will go over how I implemented each file (and my struggles along the way).
I am not that familiar with Llama but this was a good exercises to get more familiar with the model - by jumping right into the action. I look forward to learning more and more while going through CMU's ANLP course.
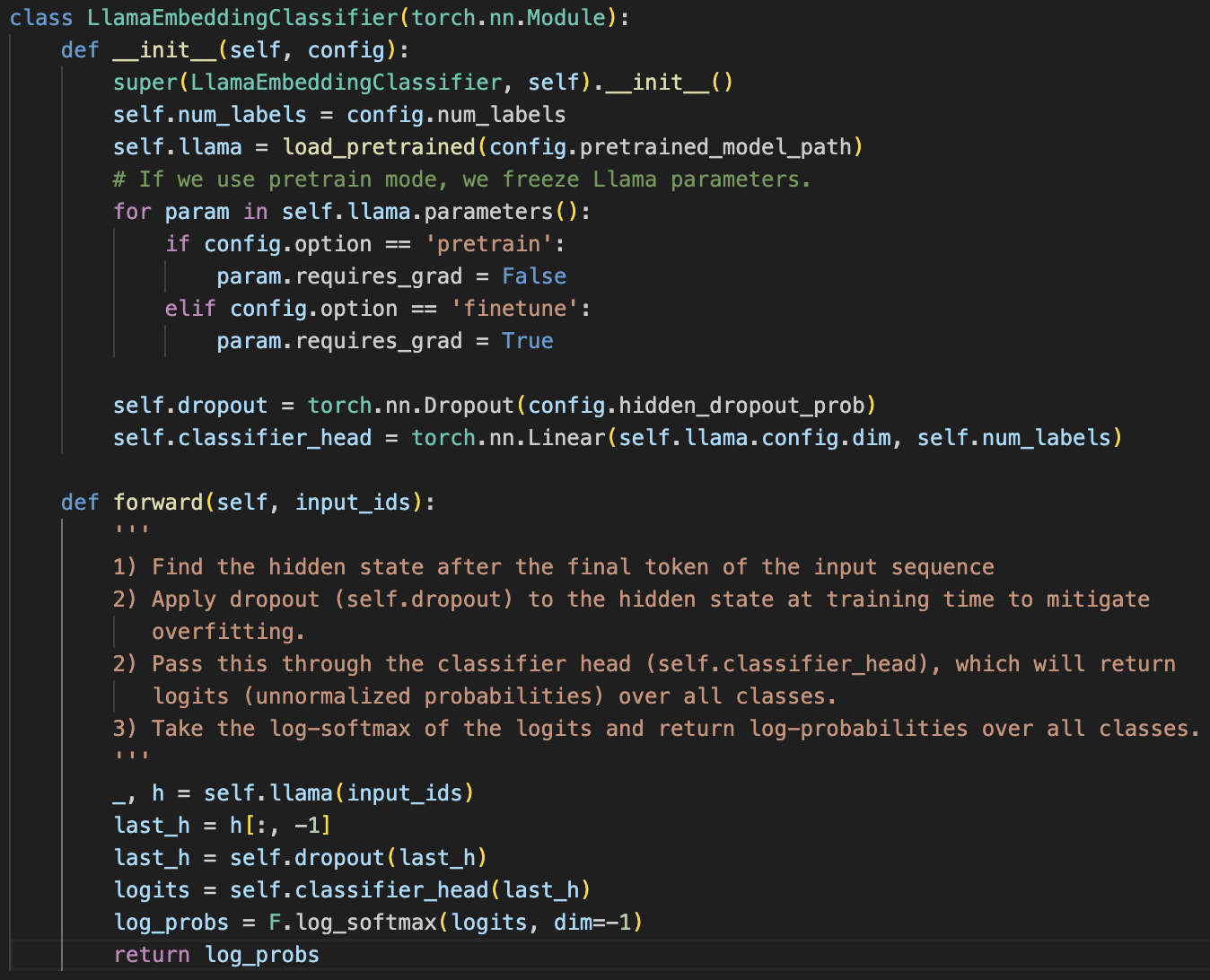
1) LlamaEmbeddingClassifier - classifier.py
This was the easiest part of the assignment, implementing the forward method of the LlamaEmbeddingClassifier, and the instructions are pretty clear.
2) Adam from scratch - optimizer.py
This one was so fun and cool to implement. While writing it I had to read the Adam paper (Kingma & Ba, 2014). In notaion it is:
In code it is:
In the exercise notes it says 'we are doing the efficient version' and to be honest I was not sure where that was in the paper, so at first the optimizer_test kept failing, but then I read the paper carefully, and found it here (a bit under the above notation):
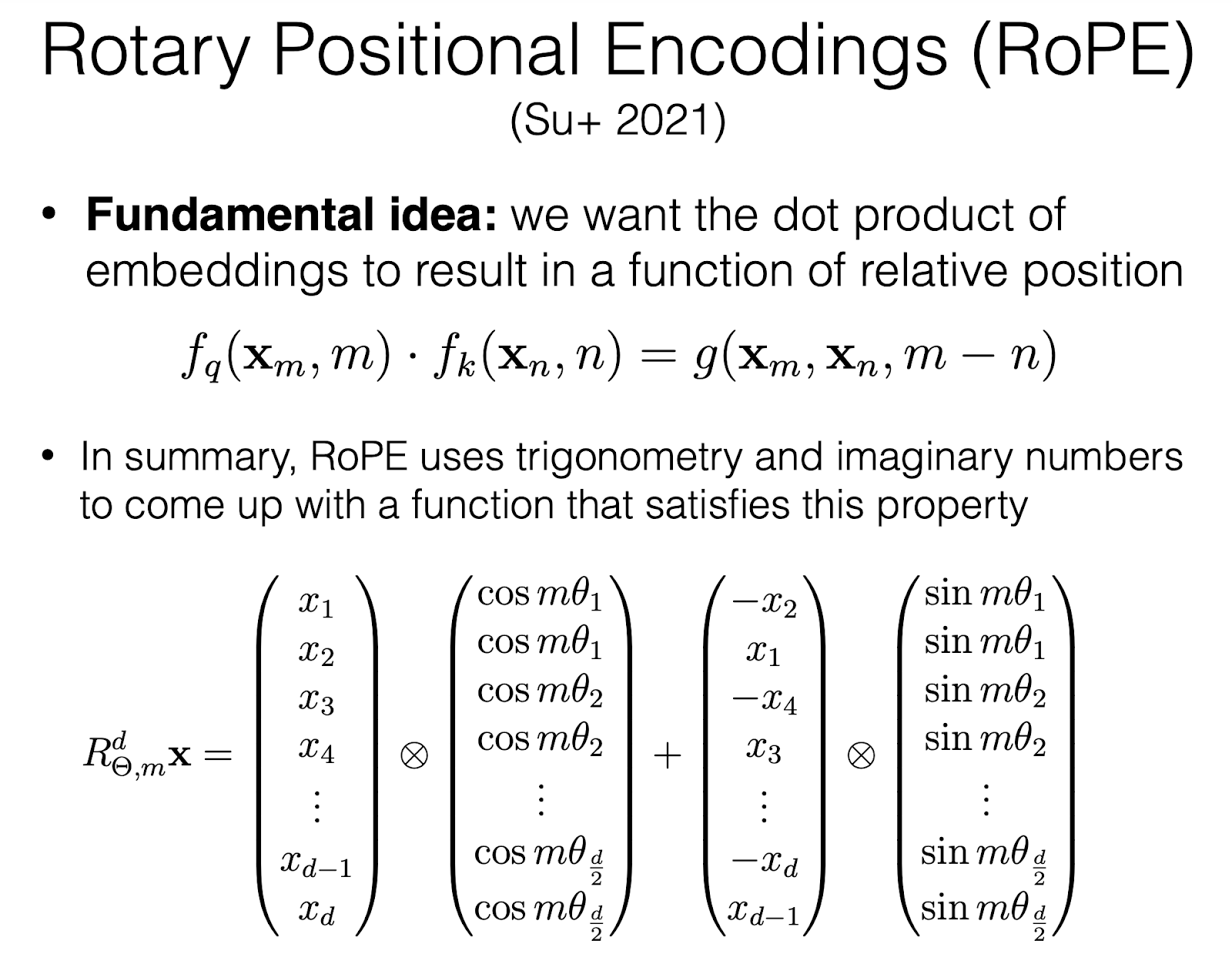
3) ReFormer: Enhanced Transformer with Rotary Positioning Embedding - rope.py
This was... something.
Apparently, it is a unique form of position embedding that uses rotation matrices to encode absolute positional information,while integrating explicit relative positional dependencies within the self-attention mechanism. It can adapt to varying input lengths and it uses relative position rather than absolute positioning which allows rope to capture contextual dependencies between tokens more effectively.
The notes recommend reading the paper to implement this code (Su et al., 2021), but to be honest, the paper confused me more rather than help me.
I tried to use ChatGPT, but the code it was giving me was not working attempt after attempt, so then I started to look for online implementations of the rotary embedding. Luckily I found
one from which I copied, the first step of the way - which was the hardest. Then I figured out that I need to use the provided helper function:
and saw that if I want to use it I need to ensure that the frecs shape fits with the query shape (query_real), alongside the frequencies (which included the cos and sin for later), positioning was needed so then the next line came. and from there it was pretty easy, following the comment instructions in the exercise and the lecture slide for the multiplication. This rope.py took the most time to get right - and for rope_test.py to pass the tests.
4) Implementing some parts of LLaMA - llama.py
RMSNorm layer - this was cool because it made me read the RMS Norm paper by Zhang and Sennrich (2019).
LlamaLayer which was straightforward following the comment instructions
generate method for inference
I am not 100% sure this particular one is correct because of the 'find logits at the final step' line. But I decided to go with it which is related to the next part.
Now, there is a sanity_check.py, and it kept failing. The sanity check, check my llama implementation, and that generate function was my main suspicion, I gave every part of the code to ChatGPT to check, but it said it is all fine. Then I decided to check the sanity_check.py and see what is the issue. The particular issue was that the logits of the test model were different from the logits generated by my model. Then I printed the max difference between the logits, and it turns out it was not that big - 2.8610e-05, to be exact. I tried to look into the code again, but nothing changed, so I decided to run the inference code that is in the assignment - test the accuracy of the model. And the results are actually good. (I added them to the readme of my github repo)

So, to sum up... wow. That was amazing. I probably need to rewatch 1-2 of the lectures before this assignment just to make sure my knowledge is sound going forward with this course, but today was great - this assignment was great practice!
That is all for today!
See you tomorrow :)