[Day 68] Build a LLM from scratch chapter 4 - making the GPT-2 architecture
Hello :)
Today is Day 68!
A quick summary of today: - Covered chapter 4 of Build a LLM from scratch by Sebastian Raschka
Below is an overview of the content with not much code. For the full code version of every step - it is on this github repo.
This chapter is the 3rd and final step from the 1st state towards a LLM

4.1 Coding a LLM architecture

The book will build the smallest version of GPT-2 that has 124m parameters, with the below config.



4.2 Normalizing activations with layer normalization



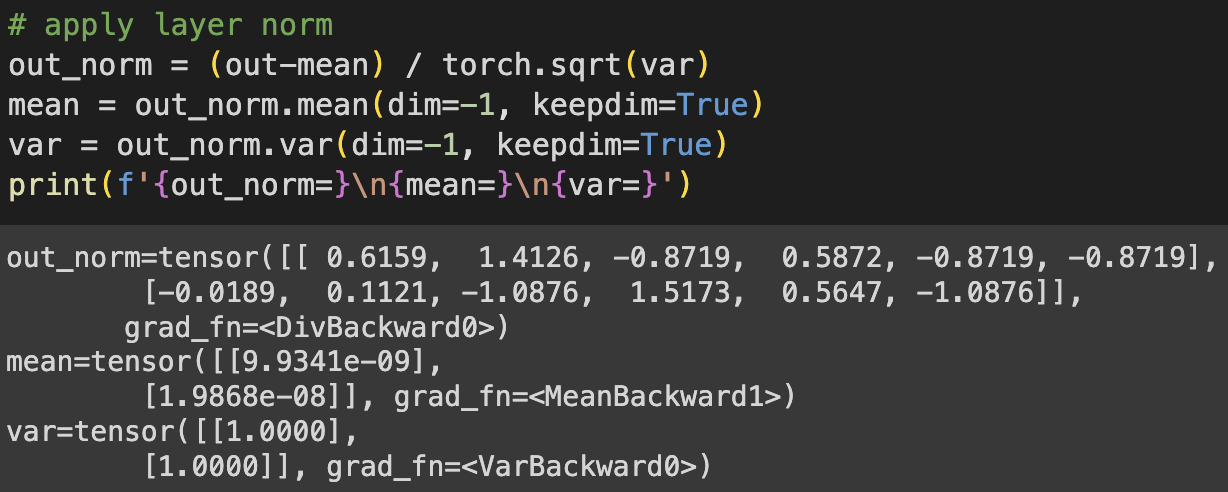
Apply layer norm, and the data has 0 mean and unit variance.

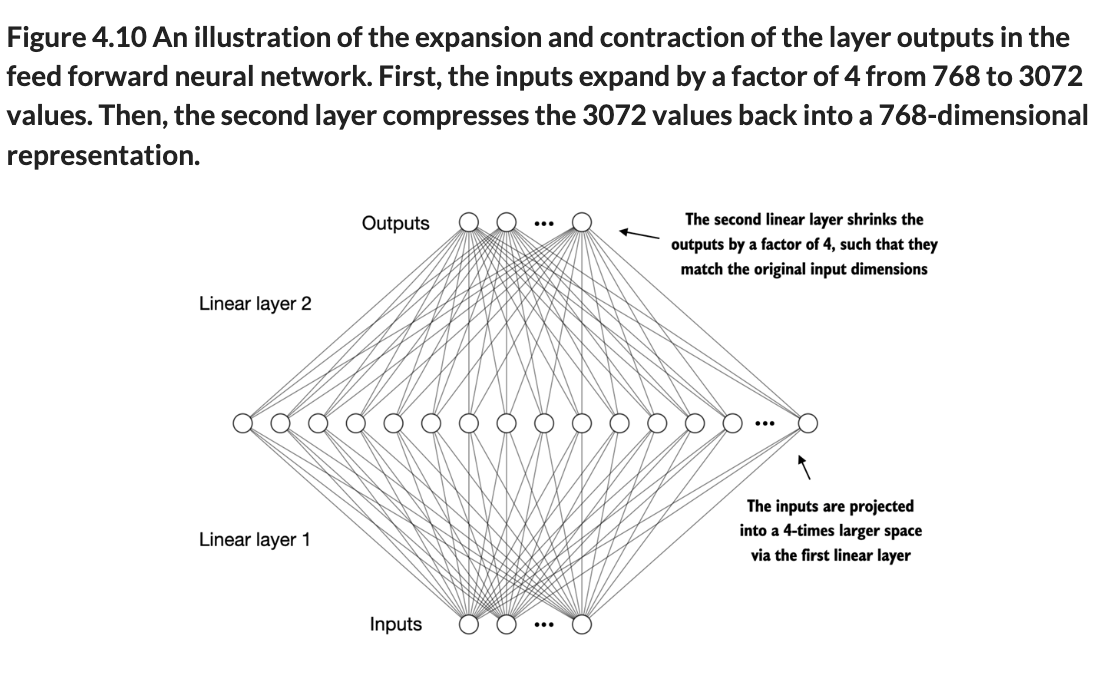
4.3 Implementing a feed forward network with GELU activations
ReLU is a versatile activation function due to its simplicity and effectiveness is various NN architectures. But in LLMs, several others are used, including GELU (Gaussian Error Linear Unit) and SwiGLU (Sigmoid-Weighted Linear Unit). These 2 are a bit more complex and incorporate Gaussian and sigmoid-gated linear units, respectively.GELU's exact formula is GELU(x)=x⋅Φ(x), where Φ(x) is the cumulative distribution function of the standard Gaussian distribution, but in practice and in the original GPT-2 model, the below approx was used
GELU vs ReLU

Using the GELU, we can then create the feed forward (FF) net.



4.4 Adding shortcut (residual) connections
A residual connection creates an easier path for the gradient to flow through the network by skipping layer/s. This is achieved by adding the output of one layer to the output of a later layer.


Now that we have figured out multi-head attention (yesterday's post and chapter), layer norm, GELU, FF network, residual connections figured out, we can combine them into a transformer block.
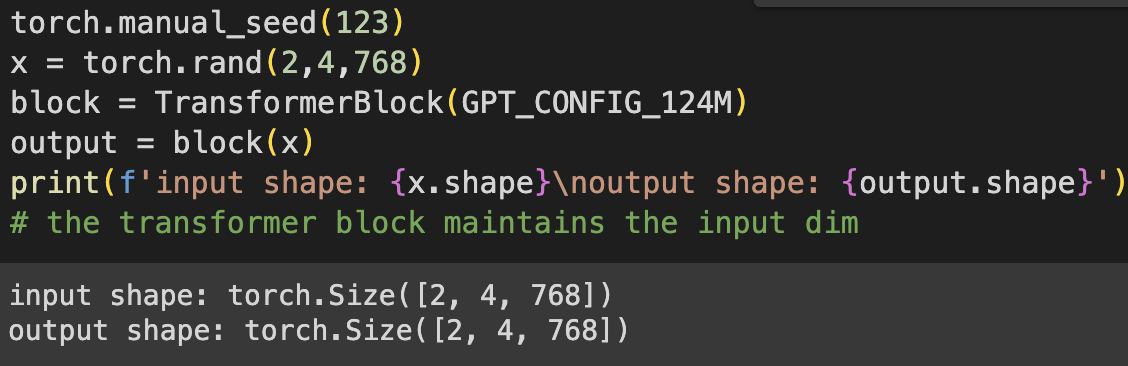
4.5 Connecting attention and linear layers in a transformer block

In code:


4.6 Coding the GPT model
At the start of this chapter we had a dummy GPT model, empty TransformerBlock and LayerNorm.



4.7 Generating text
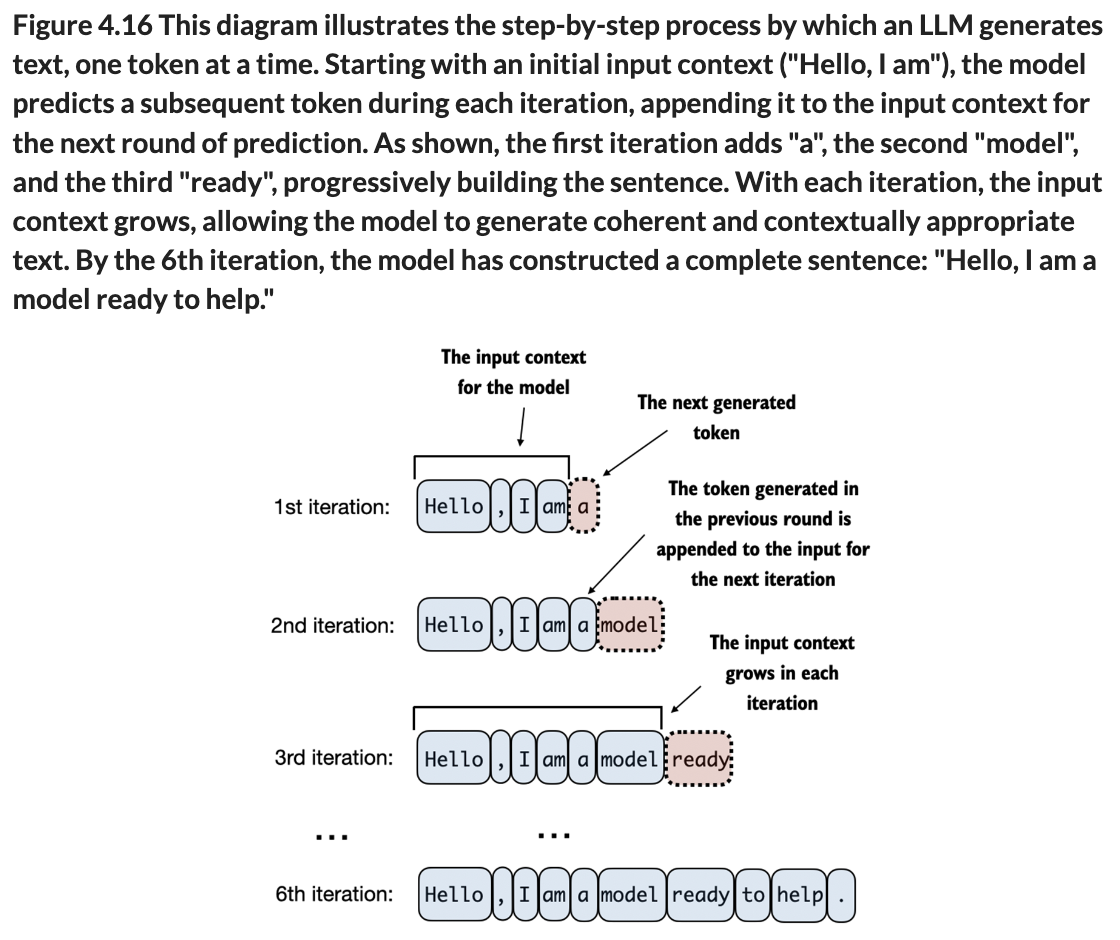

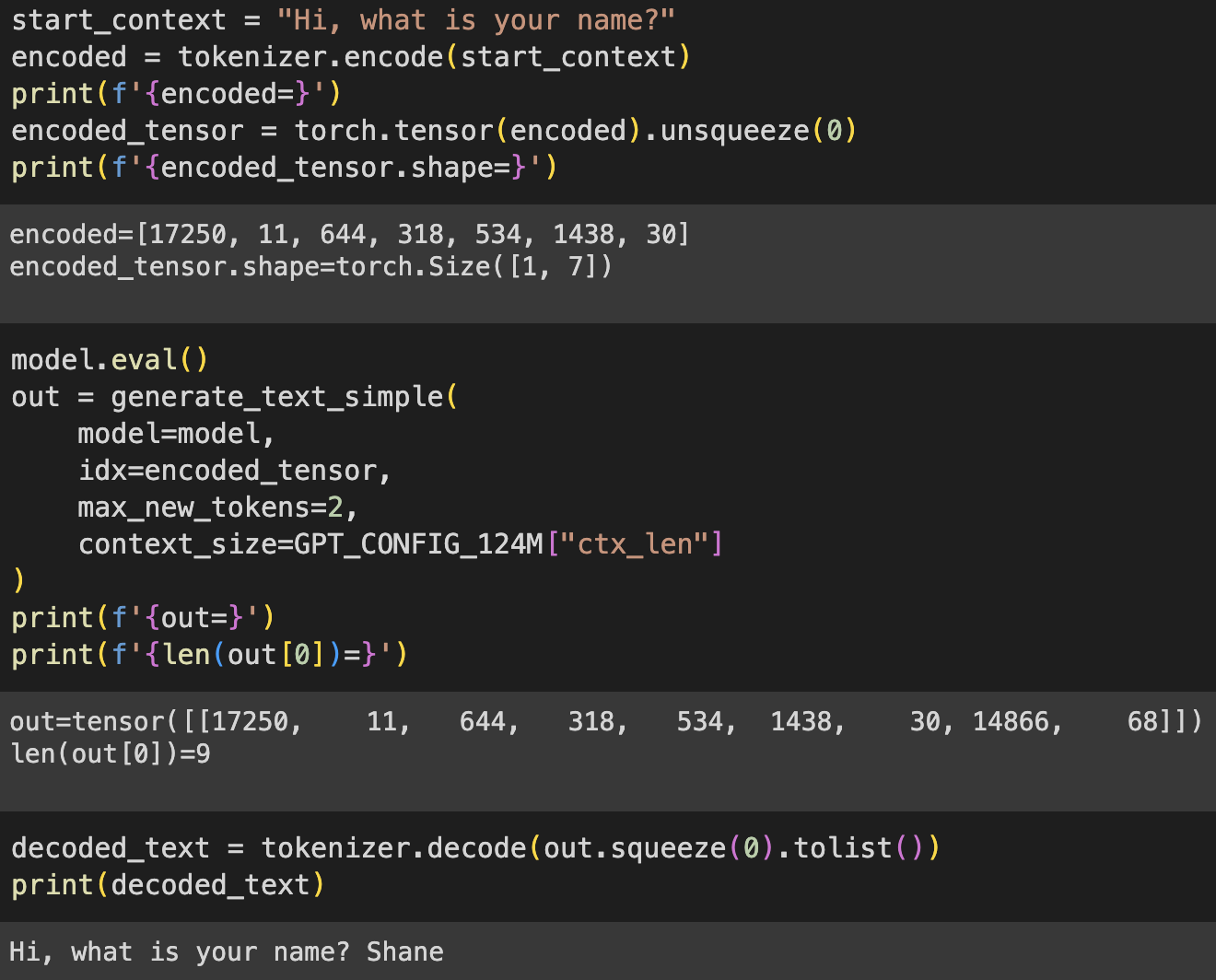

At the time of writing this, the book finishes at this point. Tomorrow, I will test the whole architecture, from chapter 2 - tokenizer + dataset creation, to now - the GPTModel, and make a training loop, and use a dataset. Now I saw there are Elon Musk tweet text datasets and Harry Potter. But we will see tomorrow :)
That is all for today!
See you tomorrow :)

