[Day 58] Stanford CS224N (NLP with DL): Lecture 2 - Neural classifiers (diving deeper into word embeddings)
Hello :)
Today is Day 58!
A quick summary of today:- did assignment 1 on google colab which covered some exercises on count-based and prediction-based methods
- Read 6 papers about word embeddings and wrote down some basic summaries
- GloVe: Global Vectors for Word Representation
- Improving Distributional Similarity with Lessons Learned from Word Embeddings
- Evaluation methods for unsupervised word embeddings
- A Latent Variable Model Approach to PMI-based Word Embeddings
- Linear Algebraic Structure of Word Senses, with Applications to Polysemy
- On the Dimensionality of Word Embedding






Next, are the short summaries of each paper. These were definitely interesting papers, I feel like I am learning the history of something big, and after a few lectures I will be in the present haha. These papers, that preceeded the infamous transformer, and that laid grounds for modern embeddings were very interesting to read.
1. GloVe paper
1. Intro
Evaluation methods for word vector models often focus on the distance or angle between word vectors. Recent approaches focus on word analogies and the two main model families for learning word vectors are global matrix factorization methods like latent semantic analysis (LSA) and local context window methods like the skip-gram model. The authors propose a global log-bilinear regression model trained on global word-word co-occurrence counts to efficiently capture the multi-clustering idea of distributed representations.
Count and prediction based methods both try to do word representations. But with glove, the authours argue that the two methods and not that different since they both operate on the co-occurance stats of the data. So the paper proposes GloVe which utilizes the benefits of the count-based (capturing global statistics), and also the benefits of prediction-based models (adding the linear substructures popular in models like word2vec).
2. Related work
Matrix Factorization methods.
These utilise low-rank approximations to decompose large matrices that have statistical info about the data. These models use matrices with raw word count and popular words like ‘the’ and ‘a’ can poison the data. To counter this, many models did transformations on the raw counts (as seen in the lecture notes).
Shallow window-based methods.
Another method is to learn the word representations by making predictions within context windows.
Window based methods do not operate directly on the co-occurance matrices (unlike the matrix factorization methods).
3. The GloVe model
GloVe wants to answer the questions - how meaning is generated from co-ocurance statistics, and how the resulting word vectors represent word meaning.
They show how meaning can be extracted through co-occurance probability



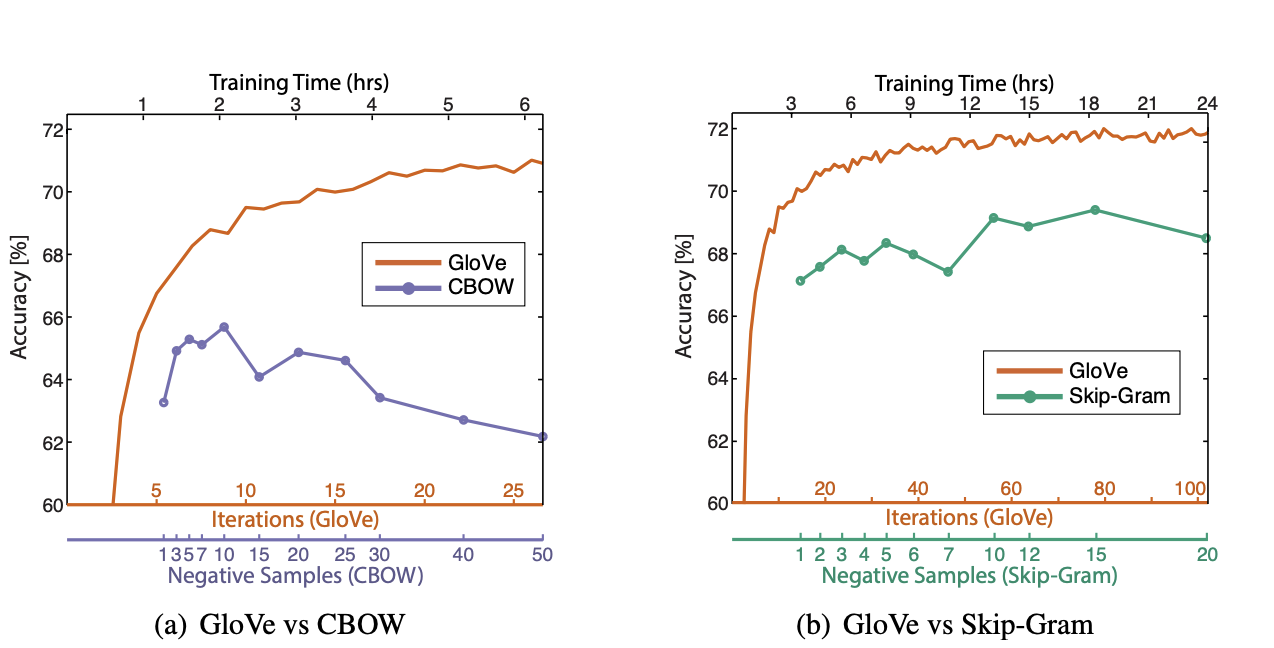
They also share the performance on the analogy task as a function of iterations.
2nd paper: Improving Distributional Similarity with Lessons Learned from Word Embeddings
1. Introduction
Recent (back then in 2014) papers suggested that NN-based models for word embeddings outperform traditional count-based models on tasks like word similarity and analogy. However much of these benefits actually come from system design choises and hyperparam optiimzations, rather than the algorithm itself. What is more, these benefits can be used in traditional methods as well, and the paper finds that there are similar gains and the difference in performance is not significant.
2. Background
The paper considers 4 word representation methods: 2 count-based methods: explicit representations (PPMI matrix) and SVD factorization of matrices, and 2 NN or prediction-based methods: Skip-grams with negative sampling (SGNS) and GloVe.
3. Transferable Hyperparams
word2vec and GloVe’s hyperparameters, for analysis purpases, are grouped as: pre-processing hyperparams (input data), association metrix hyperparams, and post-processing hyperparams (modify resulting word vectors).
Pre-processing hyperparams:
dynamic context window (dyn), subsampling (sub), deleting rare words (del).
Association metrix hyperparams:
shifted PMI (neg), context distribution smoothing (cds).
Post-processing hyperparams:
adding context vectors (w+c), eigenvalue weighting (eig), vector normalization (nrm).
4. Results
First they do a test where the hyperparams are set to default.
Next they use word2vec’s recommended configuration.
And finally, they show performance comparison when using each models’ mest configuration.

5. Recommendations by the authors
The paper does various tests and comparisons, but at the end they give some practical recommendations.
They advise to tune hyperparams but it could be computationally expensive. They give specific hyperparam numbers, but also they mention that SGNS is a robus baseline model which might not be the best at every task but does not underperform. And also it is by far the fastest to train and extremely memory and disk space efficient.
3rd paper: Evaluation methods for unsupervised word embeddings
They study how various evaluation criteria and embedding techniques, revealing different relative orderings of embeddings based on word relatedness, coherence, and downstream performance.
They also introduce a new evaluation approach focusing on individual query comparisons.
In addition, propose a model and data-driven approach to constructing query inventories, emphasizing diversity in frequency, parts-of-speech, and abstractness, and releasing a frequency-calibrated query inventory for systematic evaluation.
And, bbserve word embeddings containing significant information about word frequency, even in models compensating for frequency effects, challenging the practice of using vanilla cosine similarity as a measure in the embedding space.
All experiments are carried on the following models:
CBOW, C&W embeddings, Hellinger PCA, GloVe, TSCCA and Sparse Random Projections. And using Wikipedia dump from 2008-03-01 for training all models besides C&W, which was trained on a 2007 snapshot.
Results
The below shows the results on 14 different datasets, and the performance of the 6 models. Something to note is that CBOW outperforms on 10 out of the 14 datasets.
Results on intrinsic evaluation tasks:

Extrinsic tasks
They measure performance on a specific tasks. They find that the assumption that that there is a consistent global ranking of word embedding quality and that higher quality will result in better results, fails.
We can compare performance across tasks to gather info about a particular word embedding’s quality, but we cannot judge further that a particular word embedding can be a top performer across different tasks.
Other findings include:
Despite operating on similar input data and optimizing similar objective functions, word embeddings from different algorithms encode surprisingly different information.
Word embeddings contain information about word frequency, which affects their performance in tasks such as predicting word frequency categories and computing cosine similarity.
The amount of frequency information encoded in word embeddings varies across different algorithms. For instance, GloVe and CBOW embeddings, while both effective in intrinsic tasks, differ significantly in the amount of frequency information they encode.
4th paper: A Latent Variable Model Approach to PMI-based Word Embeddings
They propose a generative model that treats corpus generation as a dynamic process where the t-th word is created at step t, and the generative process is driven by a random walk of a discourse vector ct, and its coordinates show the context, plus each word has a time invariant latent vector vw that shows the word’s correlations with ct.
ct is a slow random walk where the meaning of discourse vector at time t+1 is obtained from the discourse vector at time t + a small random displacement vector. At each time step the probability of a word is generated by a log-linear model that relates the word’s vector and the current discourse vector.
Usual count-based methods use co-occurance matrices and for a selected k, they want to see how many times word 1 and word 2 appear in a block of k words. Using raw count matrices turned to be inefficient, so some non-linear functions started being applied. The most popular being logs, square root, or Pointwise Mutual Information (PMI)
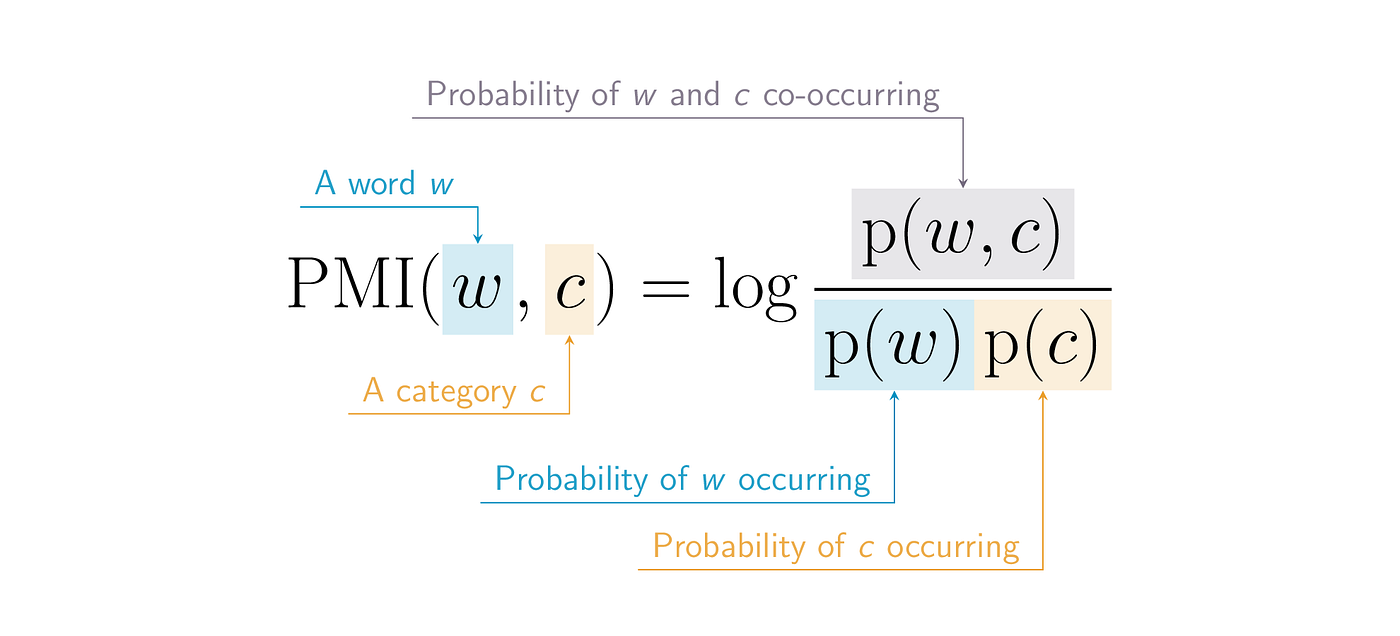
The authors argue that the previous models are like black boxes, and also there is an issue with dimensionality. The paper counters the popular assumption that simple models generalise better because their process of making word embeddings is unsupervised so the idea of generalization is not aplicable.

5th paper: On the Dimensionality of Word Embedding
The paper argues that the dimensionality on word embeddings is an ongoing mistery. It is a crucial hyperparam that directly impacts the quality of a word vector (a small dim might not be able to capture all possible word relations, while a large one can suffer from overfitting). Also, dimensionality directly impacts computational complexity which can impact a model’s applicability, training and deployment.
The proposed framework is based on the following preliminaries:
1) unitary invariance of word embedding. This means that two embeddings are essentially the same if one can be obtained from the other just by performing a unitary operation (like a rotation).
2) Word embeddings from explicity matrix factorization. Many popular embedding algs use explicit matrix factorization, including Latent Semantics Analysis (LSA). In LSA, word mebeddings are obtained by truncated SVD of a matrix M which is usually based on cooccurance like PMI matrix. This M = UDV (SVD), and a k-dim embedding is obtained by trucating the left singular matrix U at dim k, and multiplying it by a power of the trucated diagonal matrix D ->
3) Word embeddings from implicit matrix factorization
The 2 most popular embedding models word2vec and GloVe use implicit matrix factorization and optimize over some objective function using stochastic gradient methods.
PIP Loss: a novel unitary-invariant loss function for embeddings
A reasonable loss function between embeddings must respect the unity-invariance, and this rules out options like direct comparison - taking the difference. The proposed new loss - Pairwise Inner Product (PIP) loss is:
Earlier we saw that alpha can affect the embeddings’ robustness.
For alpha = 0, they find:
For alpha (0, 1] - between (excluding) 0 and (including) 1, they define Theorem 2
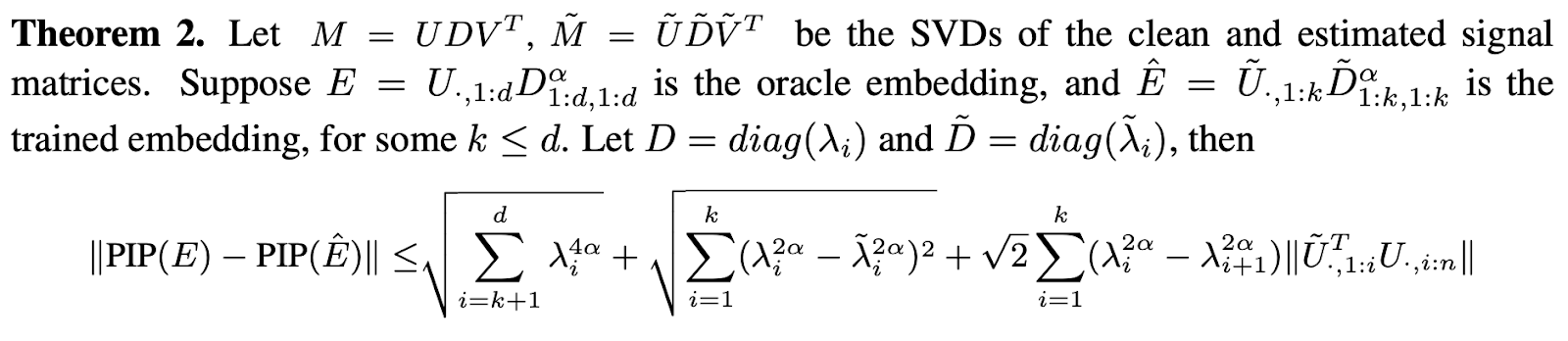
The first item is the bias as we lose part of the signal by choosing k <= d. The second term is variance on the magnitudes. The 3rd term is the variance on the directions.
The final theorem they propose shows that the bias-variance trade-off reflects the signal-to-noise-ratio in dimensionality selection.

6th paper: Linear Algebraic Structure of Word Senses, with Applications to Polysemy
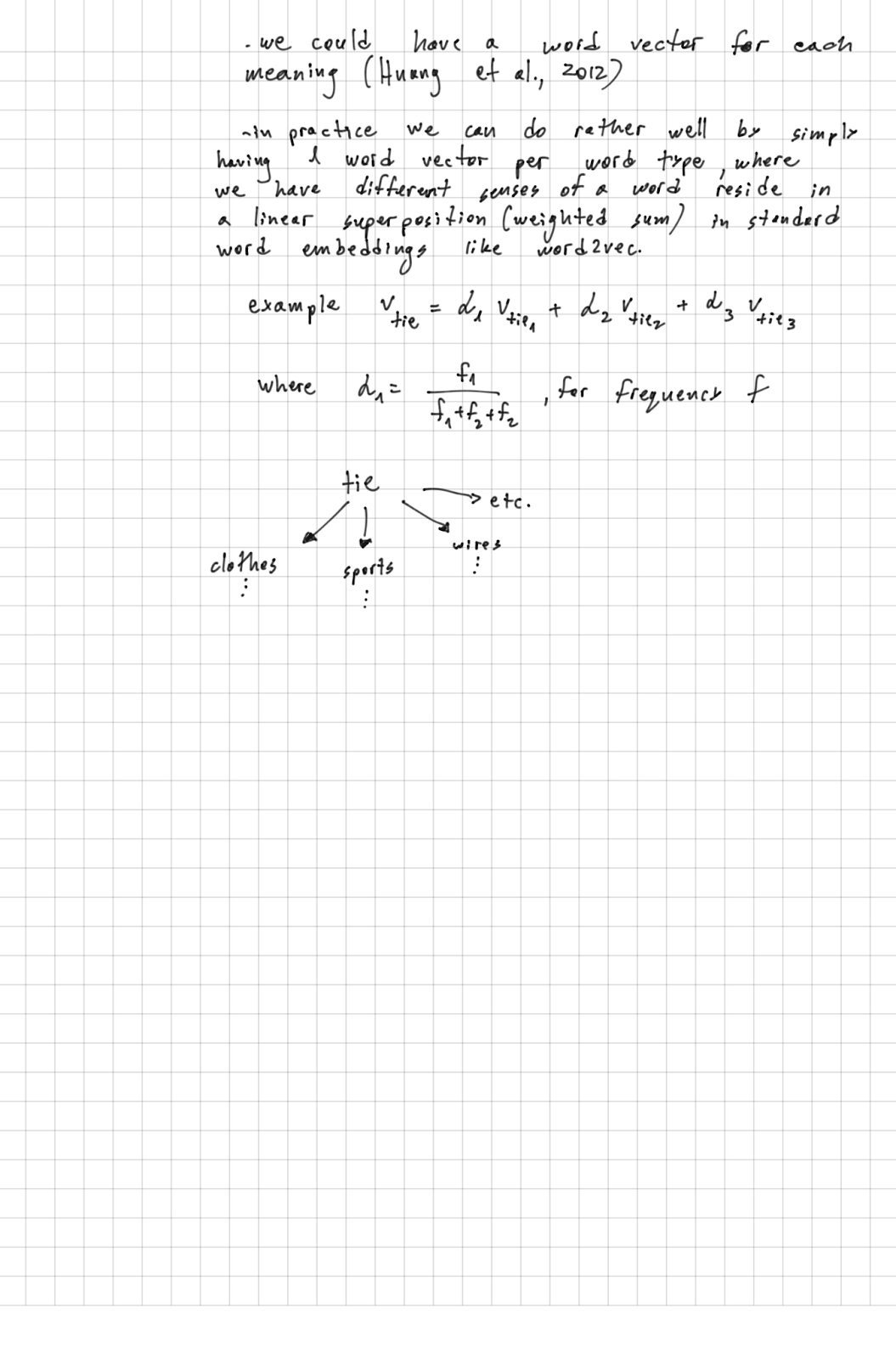
Models such as word2vec use an objective function that includes a nonlinear function of the word co-occurances matrix. This type of complexity makes it hard to understand how these embeddings caputre different meanings of words with multiple meanings (polysemous word). There have been researchers that tried to include separate meanings of words into separate embeddings. But this paper argues that multiple meanings of a word are included in the linear superposition within a standard word embedding.
The paper argues that through the relationship of a word with the words it co-occurs with, the resulting word embedding can capture multiple word meanings.
They propose Theorem 1:

They also derive Theorem 2: Assuming that embeddings satisfy


Word Sense Induction (WSI)
A task that considers the contextual information of multi-meaning words as a representation of word senses and utilizes clustering techniques to analyze the contextual information.
The paper suggests a method for WSI using word embeddings and the concept of discourse aroms that are obtained from sparse coding on word embeddings where each word can be represented as a combination of these atoms. And the paper believes that these atoms can capture the different senses/meanings of a word.
As the night went by, my summaries became 'a bit more summarised', but nevertheless the papers were nice and relatively easy to read and follow.
Tomorrow we continue with Lecture 3.
That is all for today!
See you tomorrow :)

