[Day 47] Learning a bit more about GANs and finding more KAIST courses
Hello :)
Today is Day 47!
A quick summary of today:- Looking at GANs from DeepLearning.AI's perspective
- Trying to find more KAIST courses
1) GANs with DeepLearning.AI
GANs... a war between a generator and a discriminator

How do we train GANs?
We start with the discriminator


Next,
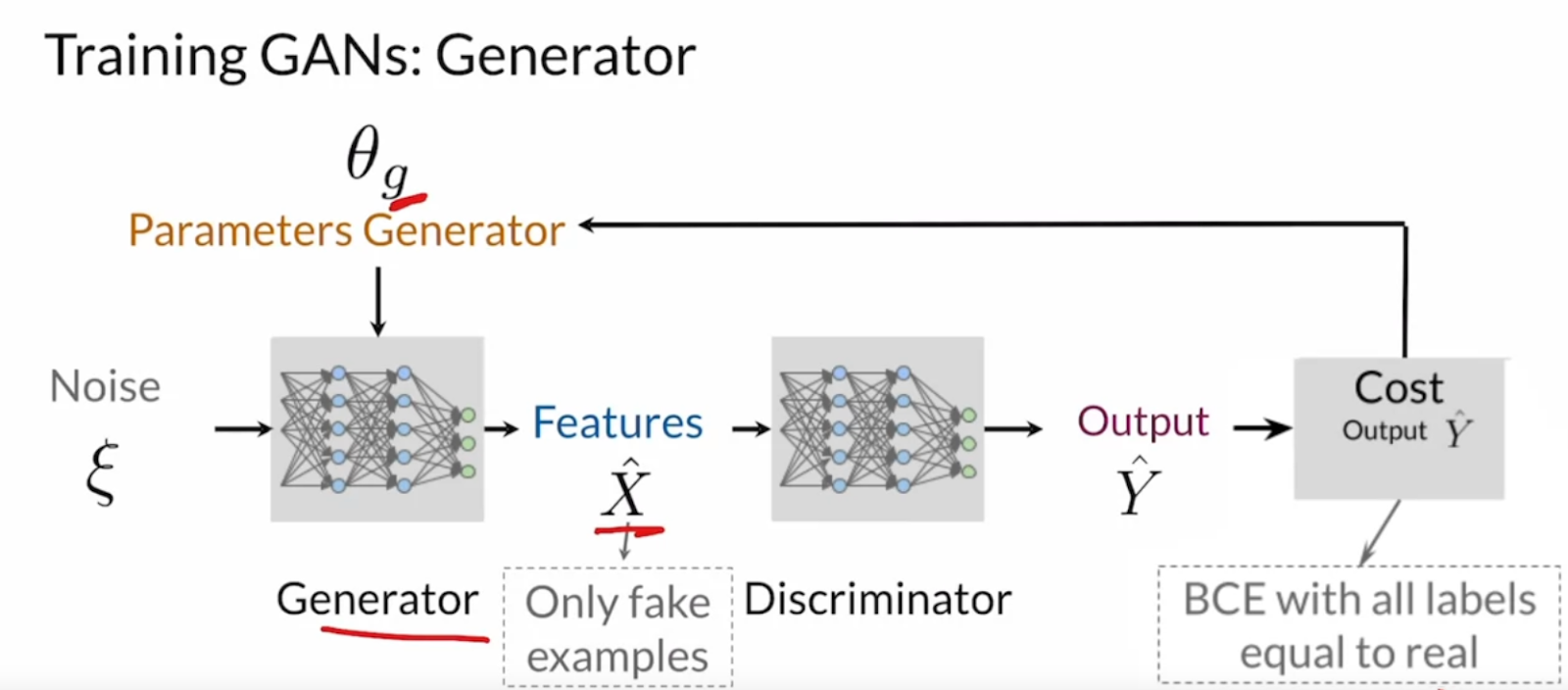

Also the reason we use random noise is so that we dont get the same image each time.
Next - problems with traditional GANs
Mode collapse - that is when the generator gets stuck one of the modes (on a two or multi-modal data) - i.e. if the discriminator gets tricked by a certain type of data x1 that is amongst x1...x100, then the generator will keep producing x1s because x1s trick the discriminator (which is the goal of the generator).
BCELoss


The generator's role is to produce images that trick the discriminator while the discriminator's job is just to discriminate (judge real or not). So many times the discriminator can start outperforming the generator very quickly. At the start the disc is not perfect so it can be harder to discriminate fake and real and will give back a non-zero gradient back to the generator.

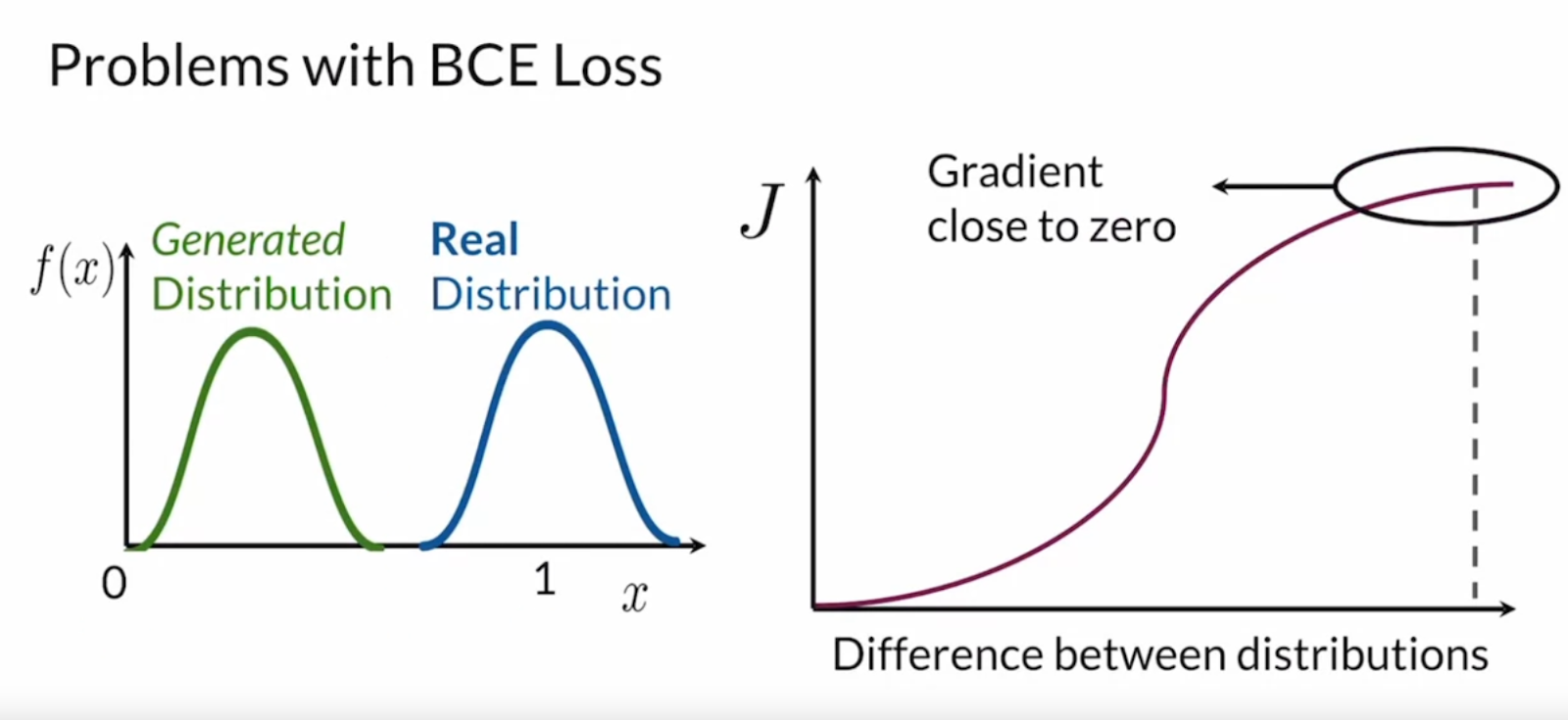
To overcome this problem, a new type of GAN arrived - Wasserstein GAN (WGANs).


It checks at every point and it assures that the w-loss is continuous, differentiable, and also it doesnt grow too much and maintains some stability during training.


But how does it enforce this ?
with weight-clipping
I learned about Conditional GANs too.
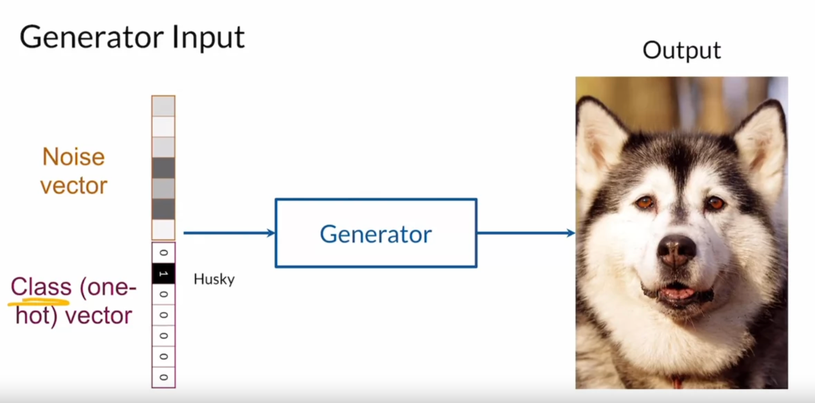

pros: better and crafting synthetic examples, can generate more labeled examples
cons: can be limited based on the training data, can overfit the training data.
I saw there are other GANs but I guess this is where my journey with GANs ended for today.
2) Finding more KAIST courses (like Professor Choi's)
Motivated from Professor Choi's great course I decided to look at KAIST AI school's curriculum and google the course whether there are slides, videos, assignments from any of the courses uploaded online. I found a few - even from KU(<happy noises>)
- Mathematics for AI (AI503, Fall 2021)
- Deep learning for Computer vision
- Recent Advances in Deep Learning (AI602, Fall 2023)
- Recent Advances in Deep Learning (AI602, Spring 2022)
- Professor Jaegul Choo's courses + videos up till 2019 (various subjects)
- AI599: Special Topics in Machine Learning : Deep Learning and Real-world Applications
- AI 603 ML Theory (KAIST 2021)
I am glad, because I found what I am going to do next ^^
That is all for today!
See you tomorrow :)

