[Day 41] A bit advanced computer vision concept review
Hello :)
Today is day 41!
Summary of today- Review some computer vision concepts that are labeled as advanced - image segmentation
- Saliency/class activation maps (CAMs)
To begin with - image segmentation, aka the process of partitioning an image into multiple segments or regions based on certain characteristics such as color, intensity, texture, or semantic information with the goal of simplifying the image for potentially better analysis.
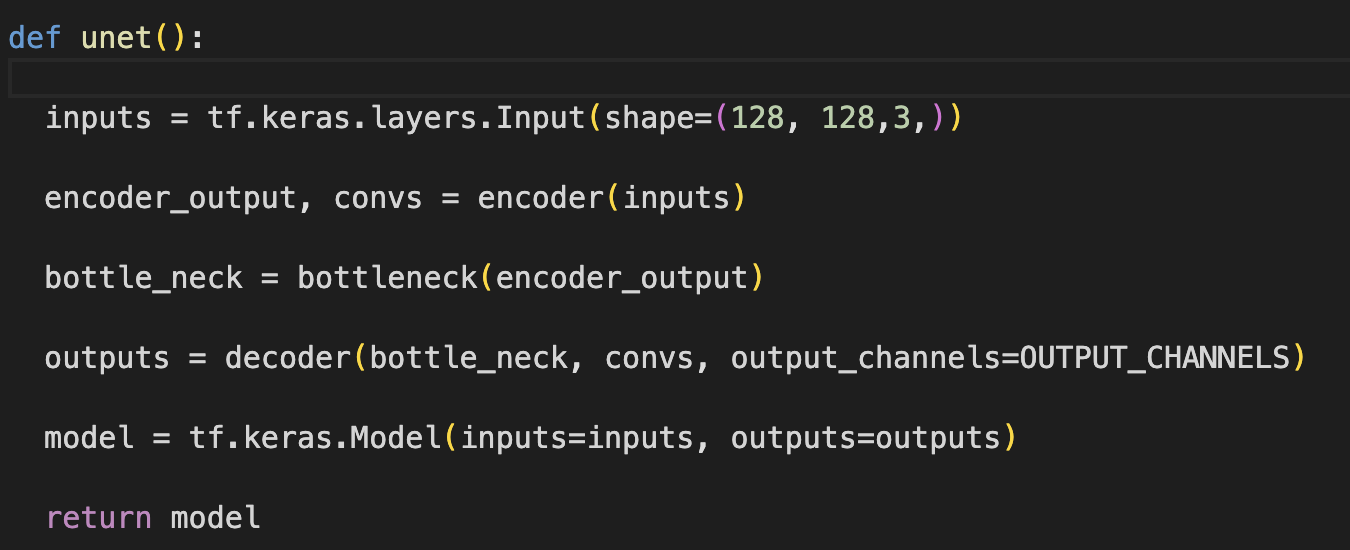
Some popular models are - SegNet, UNet, Fully convolutional network (FCNs).

Another one - which I learned about before, but did not have the chance to implement is UNet.

It's a DL architecture originally designed for biomedical image segmentation (as per the original paper haha). It features a symmetric encoder-decoder architecture with skip connections that help preserve spatial information, making it effective for tasks where precise localization is crucial. (Later there are pictures where I made a UNet using TF)
As for FCNs, there are three that I saw - FCN-32, FCN-16, FNC-8.



the number at the 8, comes from how we will upsample before the last layer (as seen in the pics)
The type of image segmentation I tried is basic, on single objects in pics.








And finally, stitch it all up:

I saw Mask R-CNN paper, but to understand it properly, I need to see if I can write a simpler version of its code. Using these ready pretrained models is great, and they are definitely powerful, but my goal is not some project with which I will be done with DL, my goal is to understand the basics of the popular networks, and even if I cant train them myself, writing a simpler (and similar) structure is helpful!
Mask R-CNN is used for not only, segmentation, but also it does detection and localization like in the image below:

To better understand how CNN models work, how the layers see images, what pixels are important, there are some established methods to 'look under the hood' (besides the ones I saw today, there are others too)
1) Class activation map (CAM)
From a CNN model, we take the last pre flattened layer and the output dense layer (like in the img)


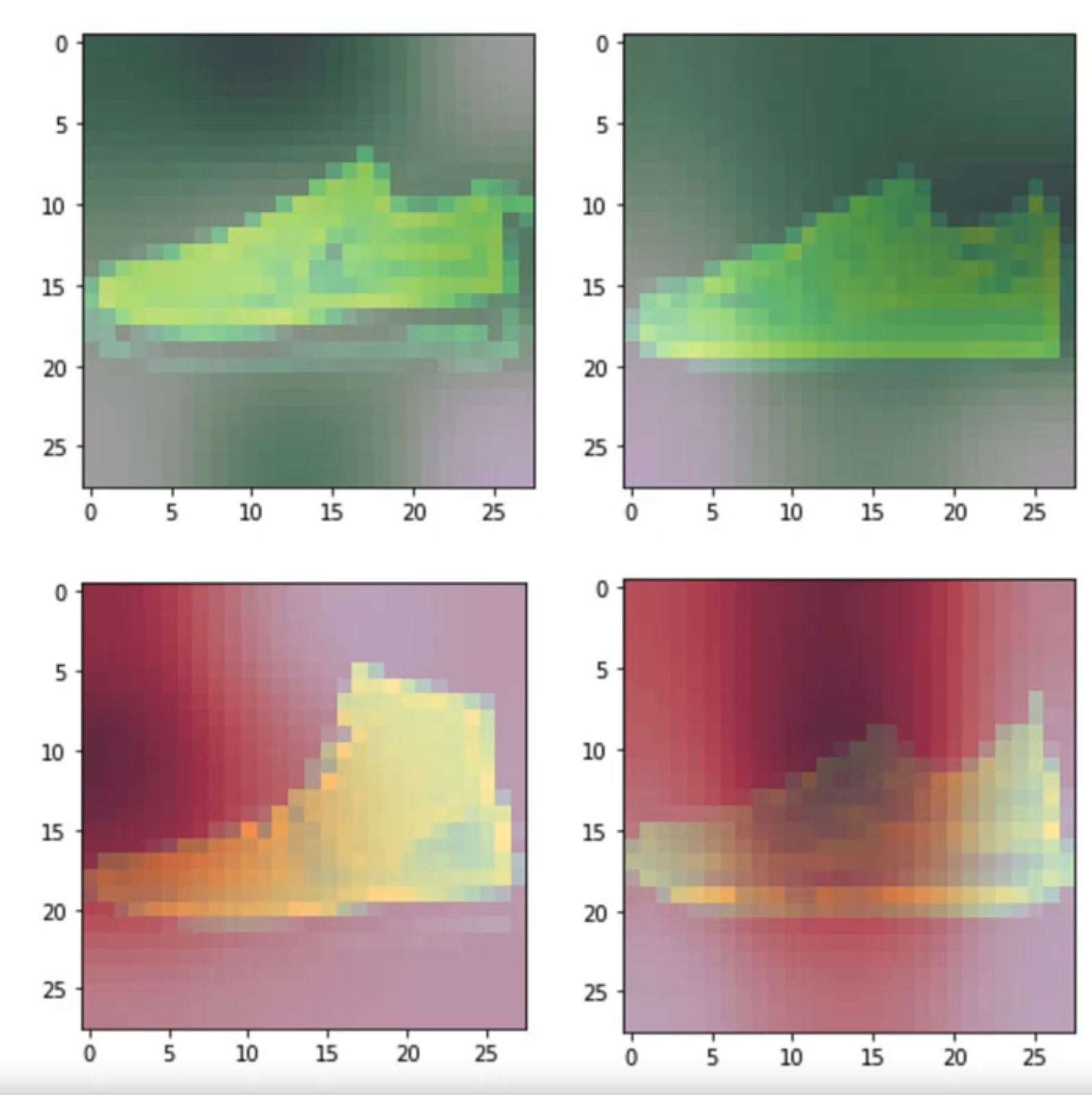
As for saliency,

it refers to a method used to understand and visualize which parts of an input image are most influential in the network's predictions. More specifically it involves analyzing the gradients of the network's output with respect to the input image pixels. In the pic we can see that this particular model looks at the animals eyes (also the noses) to determine whether its a cat or dog (the dataset contains images of cats and dogs).
See you tomorrow :)

