[Day 38] Traffic sign classification and bbox model-PyTorch and more of Andrej Karpathy's talks
Hello :)
Today is Day 38! (decided to do this one in English)
Today's summary:
These days I stay till late, studying and then writing these blog posts ~
Firstly, the model that I struggled to make yesterday - a model where I give it a picture of a sign, and what I get back is - what kind of sign it is + the sign's bounding box. And today, I am happy to say that I got it :)
The dataset I used looks like this:

For the processed version, I took the bounding box (bbox) data, the ClassId and the path.
Augmentations - only resize to 112x112 (3 channels by default). Used the albumenations library since it rescales the bounding boxes alongside the image, so no extra resizing for the bbox size was needed

An example image from the data:

The classification model was the same as yesterday, a variation of AlexNet.




In the end, I am glad, this is my first more complex model. And I also used transfer learning for the 1st time too. Of course this is a very simple, give an image of a sign, get back its classification and bounding box, model but going forward making it more complex, making multi-object classification + bbox models is a good idea.



1st one - At ICLM 2019 about Tesla's AI, and 2nd one - AI for Full-Self Driving at Tesla
Both around 30 minutes, and covered similar materials, which I will try to summarise below through some screenshots I took





So, next the model started to have a variety of inputs and classes (other vehicles, road markings, people, signs, traffic lights, environment, crosswalks, lane lines, etc.)

And identifying each task has additional sub-tasks. For examples, vehicles can come in many shapes and forms


Given the complex nature of the problem, calculating loss, proper training time, regularization is hard because some tasks have a lot of info (i.e. seeing cars) but other might have very little data.
He gave a funny example, early stopping is fine when we have 1 task:

But what happens when you have *many* ?

His 3rd talk - Tesla AI day 2021
He mentioned a little about the structure. The take 1280x960 sized data from the cameras.
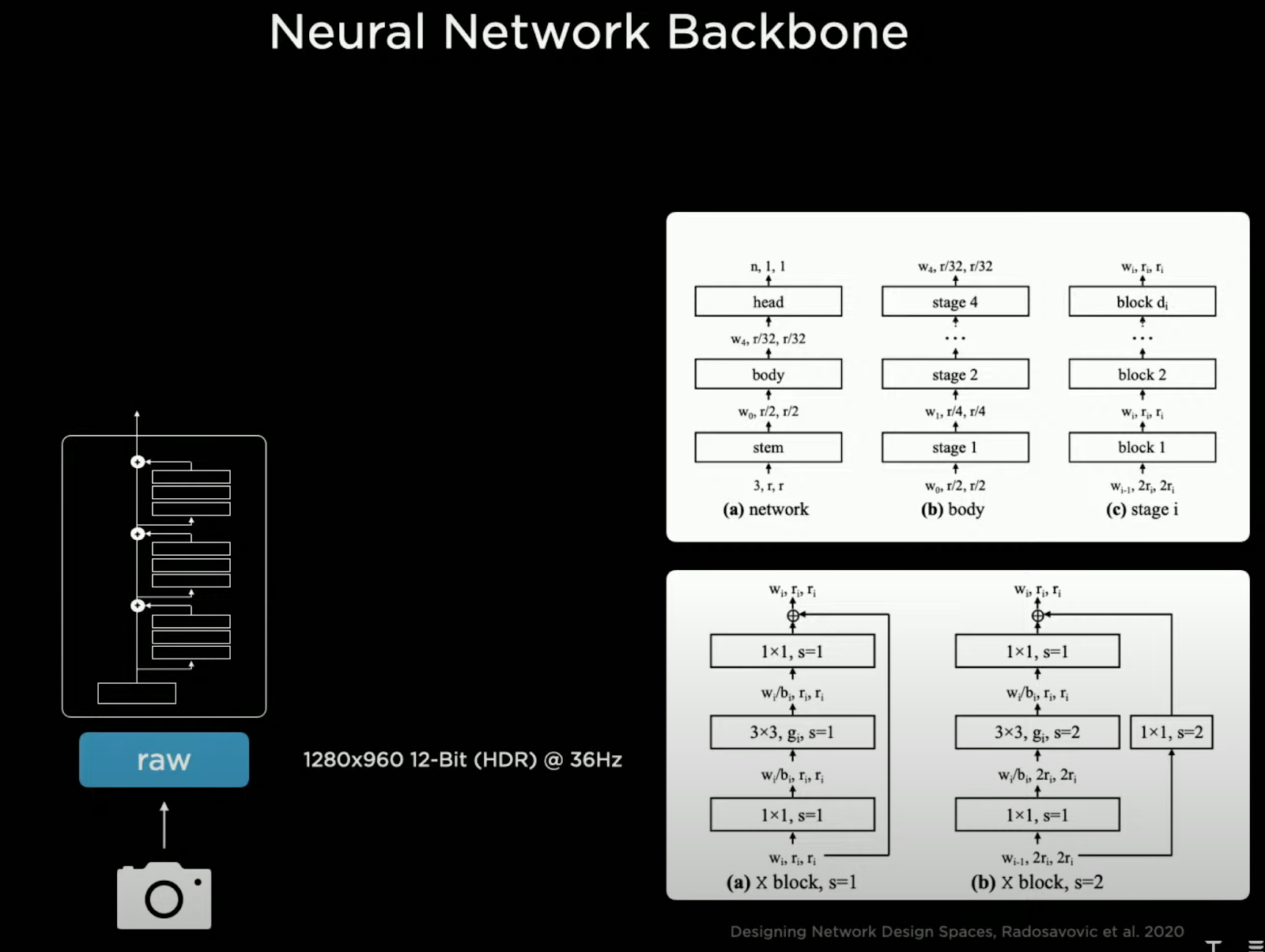

Going from more bigger picture with less channels, to a more detail and abstract picture with 512 channels.
A high level explanation would be, these pictures are put afterwards to each task, and afterwards the model tries to understand the area it is in. They use 'multi-camera' fusion. For example, 1 long truck may appear on multiple cameras, and instead of each camera trying to identify the truck on its own, the cameras can pass info so that the whole truck is identified. He gave examples with cars passing by, because when that happens, multiple cameras will see the car and we will get multiple recognitions of that car (orange) from each single camera, but by using multi-camera, the vehicle can have 1 smooth represetation.

I am not able to understand completely such complex structures yet, but seeing the path ahead is exciting! I need to start reading research papers to broaden my knowledge on models and what is happening in academia.
That is all for today!
See you tomorrow :)

