[Day 31] 자연어 처리 모델 및 소프트웨어 공학 학회 day 2
안녕하세요!
오늘은 Day 31입니다!
오늘의 내용이 다음과 같다- 학회 day 2
첫 번째 ~
Deep Learning specialization by DeepLearning.AI 거의 끝냈다
남아 있는 부분이 많지 않고 내일 다 할 것 같다
오늘의 부분은 자연어 차리 모델에 대한 것이였다
RNN 모델이 자연어 처리를 잘 할 수 있는데 그보다 Gated Recurrent Unit (GRU) 모델은 더 효과적으로 할 수 있다. RNN 모델은 장거리 관계의 기억이 잘 못 하여 GRU 모델은 그 단점을 극복한다. 또 RNN 모델이 vanishing gradient 문제도 있어서 GRU는 그것도 극복할 수 있다. vanishing gradient은 back prop 할 때 거리가 길면 gradient이 너무 작아지고 없어지는 문제이다.

Next ~ word embeddings.
Whereas other methods may use indexing of words, or characters when making text generation models, we can use analogies and word vectors. With the first methods, we might end up with 50,000 classes (if we have 50,000 unique words), instead of that, we can use analogies to group words together.


Word embeddings encode semantic similarity between words. Words that are semantically similar tend to have similar vector representations. For example, in a well-trained word embedding model, the vectors for "king" and "queen" are expected to be closer to each other than the vectors for "king" and "car".
For example, man to woman is the same as king to {x}. man is -1, woman is 1> (-1) - (1) = -2 > so we look what value with king, gives a value very close to -2. To calculate this similarity, we can use 'cosine similarity'.


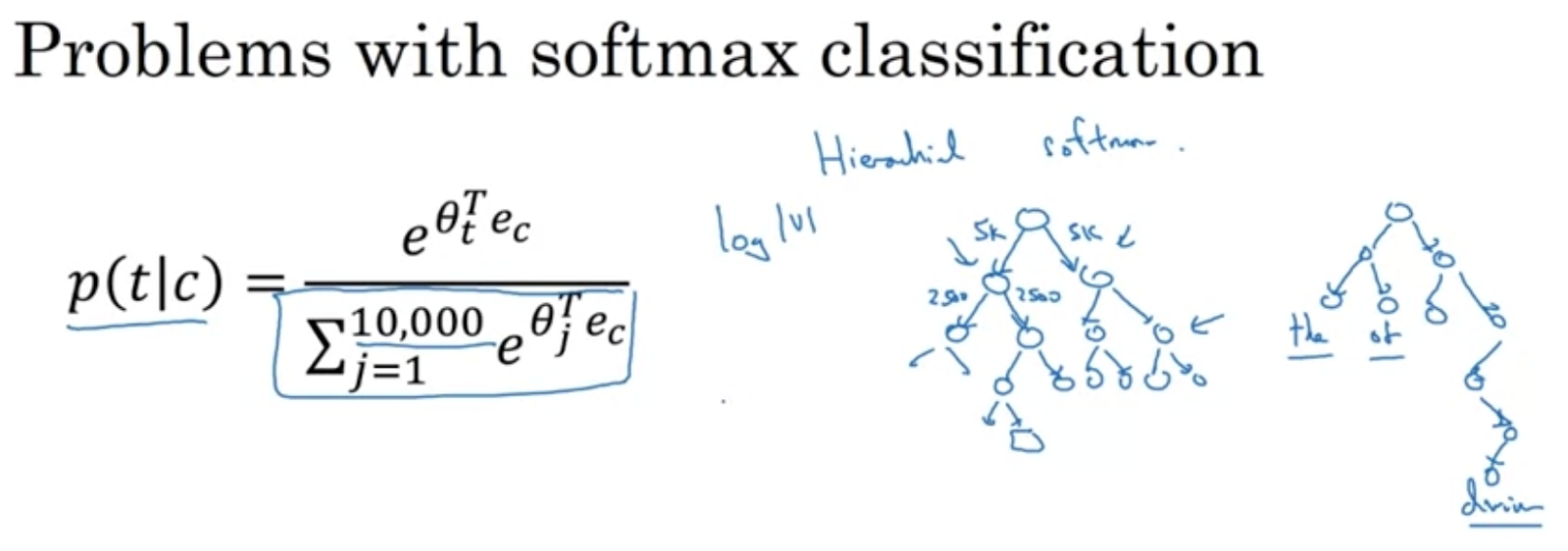
그래도 softmax도 사용할 수 있는데 이진 분류 문제로 생각해야 한다
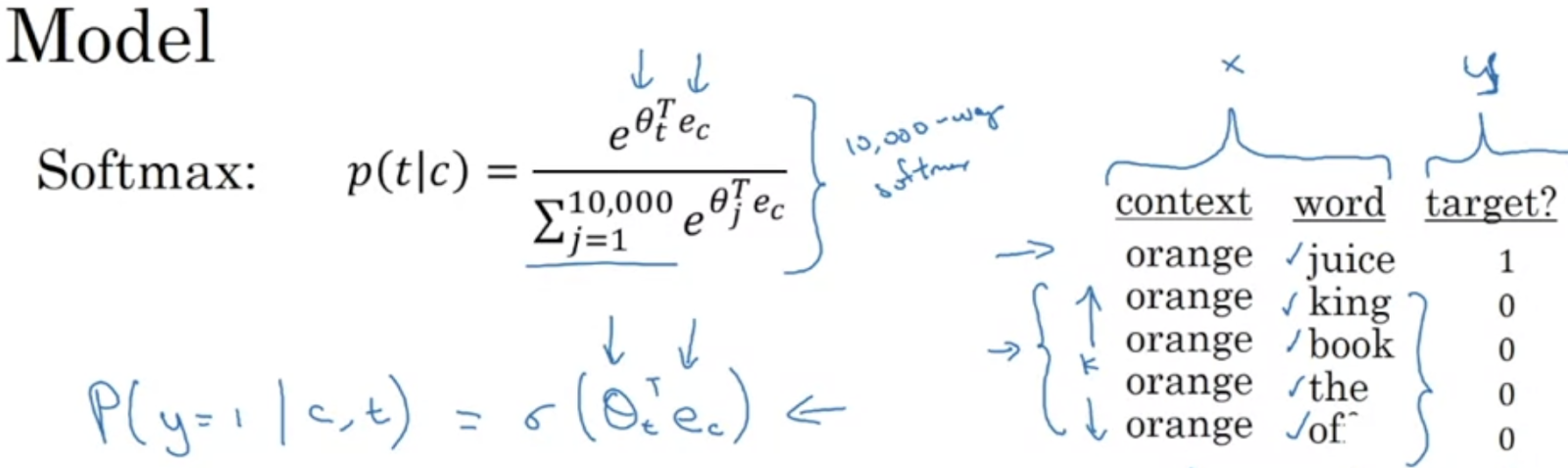
자 ~~ 오늘 참석했던 논문을 말씀드리겠습니다
The paper introduces SINVAD - a method for creating images to test DNNs with images that very closely resample the actual image. For example, the presentor showed images of numbers, 7 and 9, where both numbers could be seen in the image (a confusing image even for humans), and the point was to create images that try to deceive the machine.
다른 논문도 봤는데 이건 특히 기억에 둔 것 같다. 좀 재미있었다
저자 응웬당칸, 응웬민득, 파우델 쁘러베스, 양형정 (전남대)
What got stuck in my head was that the authors want to create natural face videos that listen to a call, conversation. When we communicate, one person talks, the other listens, and the listener usually does a little smile, or nod, other small gestures with their face, and the authors looked into making a model that generates such faces, when given an input 'talker', so the result of the model is the 'listender'. In the ppt, they showed some funny show videos of the generated face, but I did not record it, and neither it is in the paper above.
내일은 마지막 날이고 제가 발표할 날입니다. 내일의 글에 발표 자료를 넣어 두고요. 준비는 한국말로 했는데 내일 좀 긴 내용을 좀 더 빠르게 발표하기 위해 영어로 하겠습니다. 그래도 학회에 참가자 영어 자연스럽게 하시는 것 같아서 문제없이 발표했으면 좋겠습니다. 이해가 잘 안 되는 부분이 있는 경우 한국말로 설명을 하겠습니다.

지금 11시56분이라 자야겠다 ~
오늘은 여기까지입니다!
내일 뵐게요!

