[Day 9] CGPA 예측 단순 선형 회귀 모델
안녕하세요!
오늘은 Day 9입니다.
오늘 단순한 예측 모델 구성해 봤다.
데이터는 clean이며 다음과 같다

간단한 시각화도 만들어 봤다


CGPA 高 => placement = 1 확율도 高
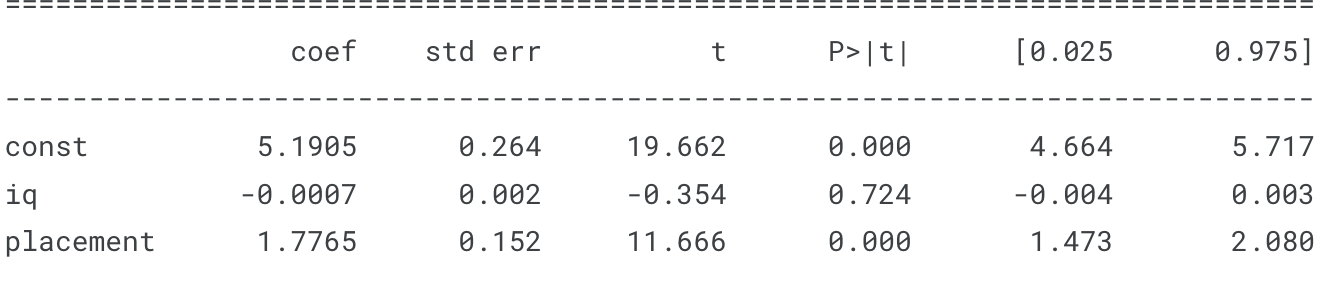
IQ는 상관없는 것 같다


그냥 재미로 ~ 피처는 iq와 placement, 목푯값은 cgpa로 택했다
scikit-learn의 LinearRegression()으로 R-squared은 0.69937나왔는데 statsmodel로 구성했던 모델와 비슷하다.
오늘은 이상입니다.
내일 뵐게요 ^^

