[Day 29] Object detection 어떻게 되는 것일까?
안녕하세요!
오늘은 Day 29입니다!
오늘 공부했던 것은
이건 course에 week 3 부분이다

1. Classification with localization
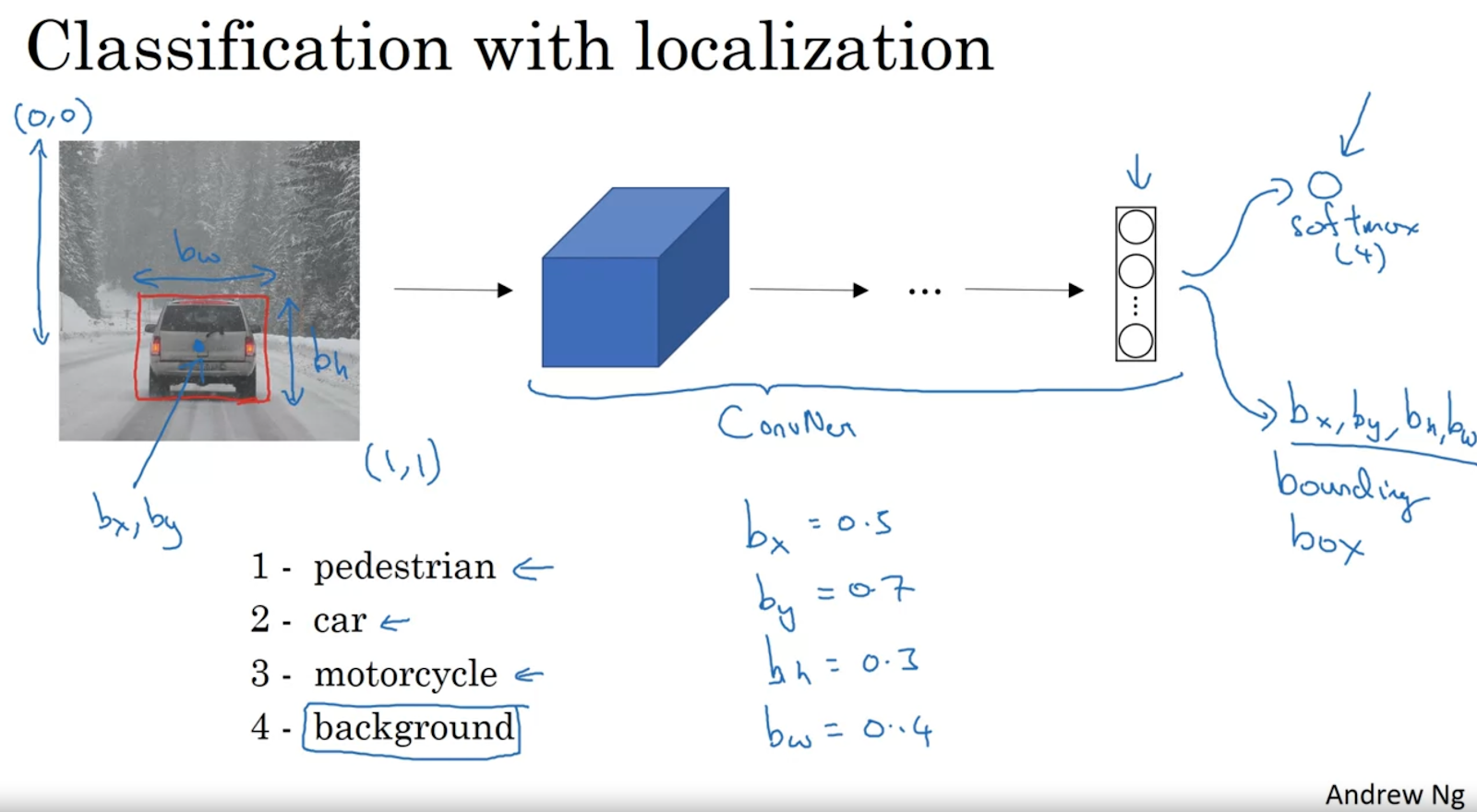

그런데 이런 모델 어떻게 훈련할까?
우선, 차 있는지 없는지 분류 모델 훈련하고서 Sliding windows detection 방법으로 차가 있는지 없는지 발견할 수 있겠다
 그 창의 사이즈 다양하게 선정할 수 있다
그 창의 사이즈 다양하게 선정할 수 있다
그런데, 이 방법의 비용이 너무 크다고 발견했다, convolution으로 할 수 있는 방법이 만들어졌다
위에 경우에 square 하나씩 하나씩 창을 움직인데 convolution implementation으로 한꺼번에 다 할 수 있게 되었다

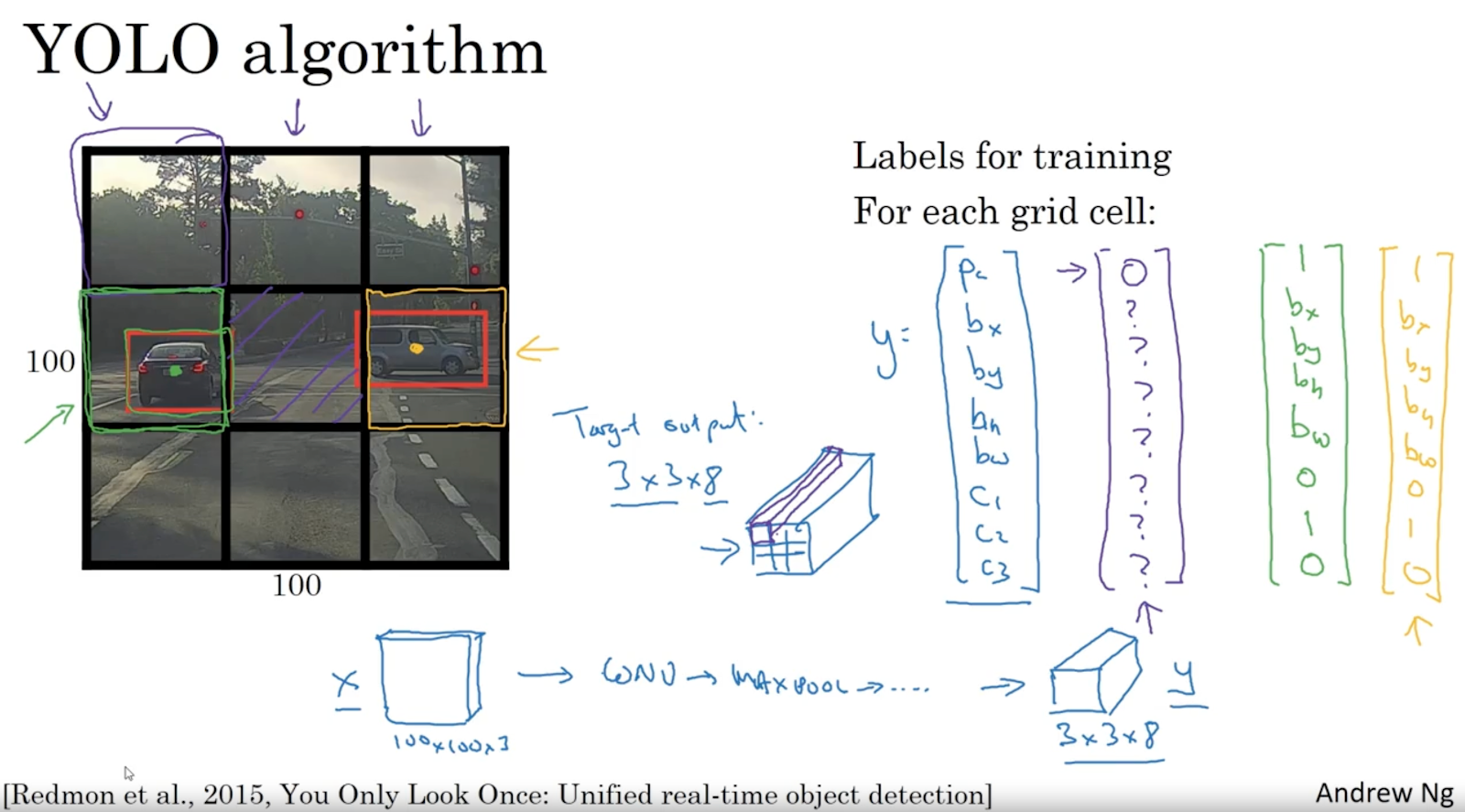
'Grid based approach'으로 사진이 여러 가지 창으로 나누고 그 창에 안에 있는 object의 bounding box와 pc (object 있는지 없는지 확률) 계산한다
3. Object detection 평가

예측 bounding box와 정말 bounding box 있으면, Area of overlap (황색)과 Area of union (청색)으로 IoU 계산할 수 있어서 평가를 할 수 있다


4. Anchor boxes

그러니 anchor box 2 가지 정의 하면 output에 anchor box 정보도 포함할 것이다

5. Region proposal (R-CNN)








U-Net의 implementation 어려울 텐데 나중에 학회 후 한번 해 볼 것이다!
내일부터 KCSE 2024 학회 시작하여 사흘 동안 독학으로 배우긴 많이 할 수 없을 것 같은데 학회에서 발표될 내용의 요약해 드리도록 하겠습니다.
제 발표는 2월3일이고 기대됩니다!
오늘은 여기까지입니다!
내일 뵐게요!

