[Day 27] 딥러닝 모델 개선법 - 하이퍼파라미터 뉴닝, 정규화, 최적화
안녕하세요!
오늘은 Day 27입니다!
오늘은 Deep learning specialization 중 3번째 course를 공부했다
우선, 어제 시작했던 부분을 끝냈다
단순 딥러닝 모델을 'from scratch" 만들어 봤다
과정을 간단하게 설명하자면
1. initialize parameters

2. do forward prop, compute cost, do backward prop, update params

실제로 머신러닝 과학자가 이렇게 하는지 잘 모르겠는데 신경망 모델을 더 깊게 이해하려고 도움이 되었던 것 같다
자, 이제 ~ Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization의 내용을 요약해 보도록 하겠습니다!
Basic recipe for machine learning 얻었다
Model has high bias ? > Yes > Bigger network, train longer, look for another model architecture
\/
No
\/
Model has high variance ? > Yes > More data, regularization, look for another model arch
\/
No
\/
Done :)
이건 간단한 model building recipe라고 한다
Bias와 variance 극복하기 위해 여러가지 방법이 있는데 normalize 하나이다.
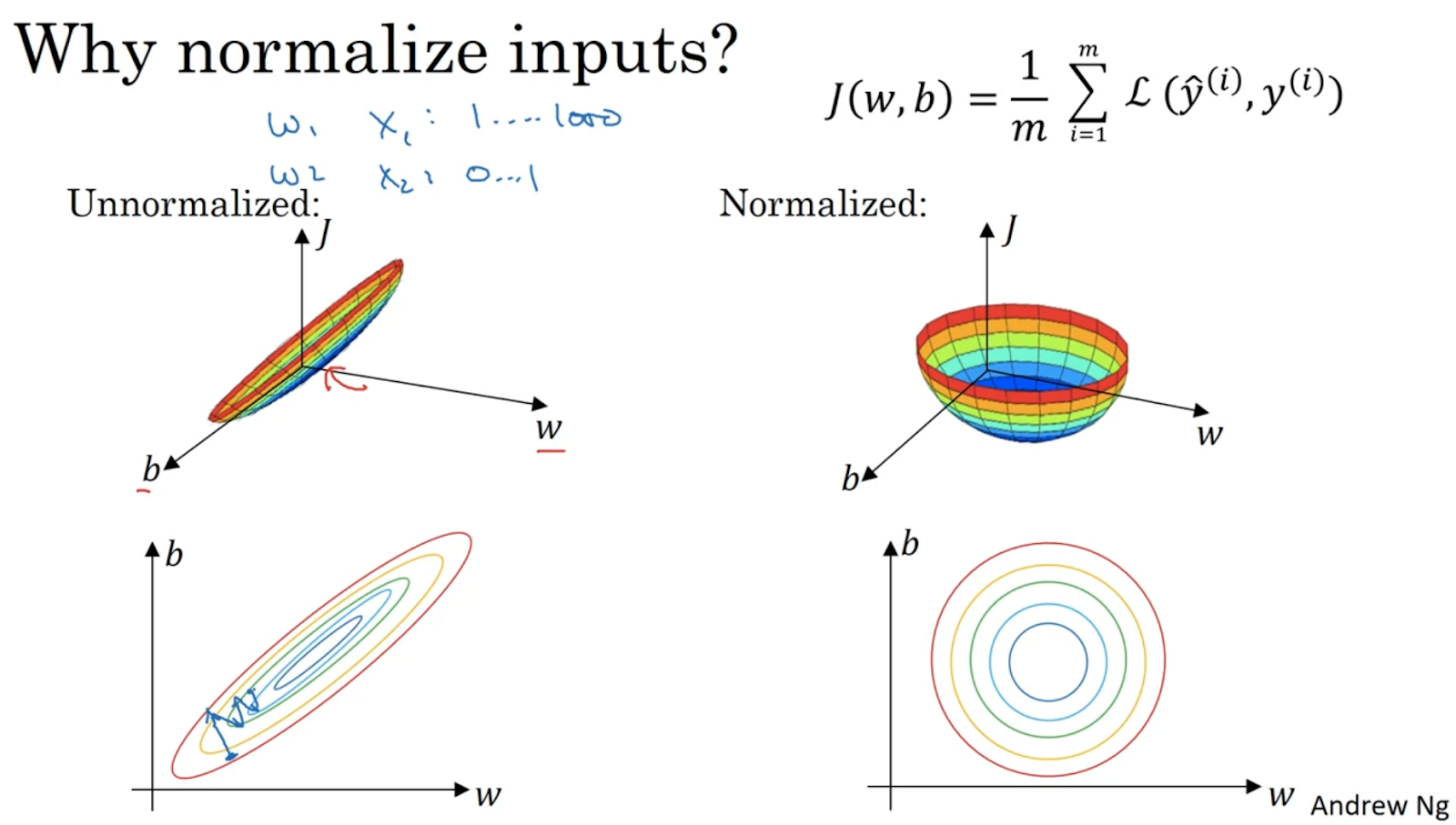
정규화 전 및 정규화 후. 정규화하면 grad descent이 minimum을 더 쉽게 찾을 수 있게 된다
Bias와 variance 극복하기 위해 W, b 파라미터 initialization도 할 수 있다
1) 다음 경우에 W, b 0으로 설정했다


2) 다음 경우에는 W는 large number인데 b 0으로 설정했다


(
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1])*np.sqrt(2./layers_dims[l-1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))*np.sqrt(2./layers_dims[l-1])
)
Different inits lead to different results. Random inits are good for breaking symmetry and make sure different hidden layers learn different things.


그 다음에
정규화 (regularization)
1) 정규화 없는 모델
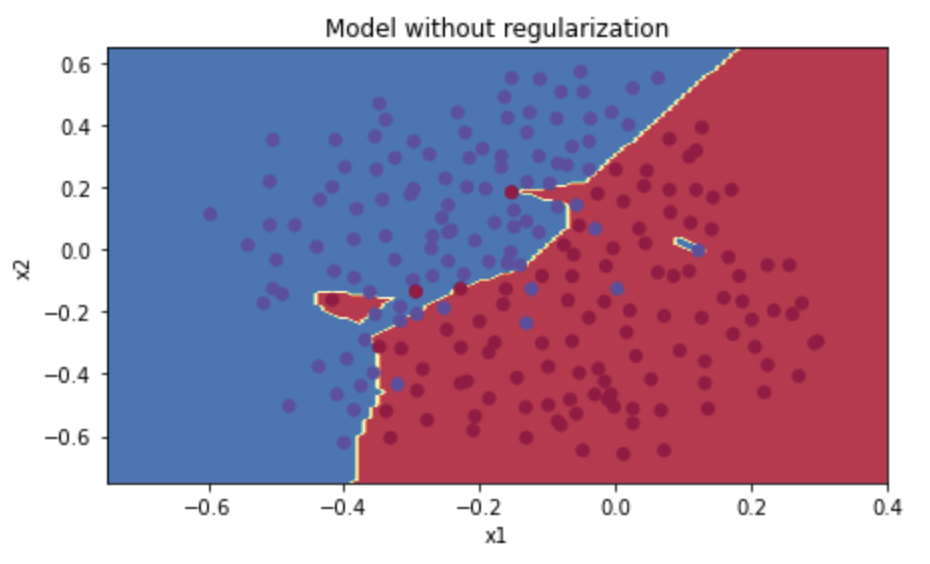





그 다음에 ~ optimization
Adam optimizer에 beta1, beta2, epsilon 하이퍼파라미터 있는지 몰랐다
학률도 하이퍼파라미터인데 위에 것에 대해 몰랐다
- Beta1: typically set close to 1 (but less than 1), controls the exponential decay rate for the first moment estimates (the mean of the gradients).
- Beta2: Similar to beta1, beta2 is another exponential decay rate parameter, typically also set close to 1. It controls the decay rate for the second moment estimates (the uncentered variance of the gradients). A common default value for beta2 is 0.999.
- Epsilon: This parameter is a small constant added to the denominator to prevent division by zero and to improve numerical stability. It ensures that the optimizer's calculations don't explode when the denominator approaches zero. A typical value for epsilon is around 1e-8.

이 중 아래 방법이 제일 유행하다고 한다

하이퍼파라미터 뉴팅 하기 위해 random search는 더 효과적이라고 한다

다른 정규화 방법은 batch normalization이다
위에 사진 보시면 z (pre-activation value) normalize 하기 위한 방법이다. 그런데 표준 편차 항상 1 안 되고 mean 0 안 되기 위해 beta and gamma 하이퍼파라미터로 여기고 튜닝 할 수 있다


오늘의 내용이 많고 재미있었다. 앞으로 forward pass, backward pass, cost, activation, normalization, regularization 등등 tensorflow로 할 것인데 이런 기초 지식이 소중하다고 생각한다!

오늘은 여기까지입니다!
내일 뵐게요!

